第一讲 嵌入式系统概述 嵌入式系统三要素
嵌入性:嵌入到对象体系中,有对象环境要求
专用性:软、硬件按对象要求裁剪
计算机:实现对象的智能化功能
标准定义:以应用为中心、以计算机技术 为基础,软、硬件可裁剪 ,适应应用系统对功能、可靠性、成本、体积、功耗等严格要求 的专用计算机系统。
核心要义:嵌入到对象体中的专用计算机系统
嵌入式系统的核心:计算技术;嵌入式系统的灵魂:软件技术
嵌入式系统的分类 嵌入式处理器的分类 嵌入式系统硬件的核心部件是嵌入式处理器,按照用途可以为分:
嵌入式微控制器 (Micro Controller Unit, MCU): 单片机
嵌入式 DSP (Digital Signal Processor, DSP)
嵌入式微处理器 (Micro Processor Unit, MPU): ARM
SOC(System on a Chip, SOC)
SOPC(System on a Programmable Chip, SOPC)
嵌入式操作系统的分类 操作系统:连接计算机硬件与应用程序的系统程序
非实时操作系统: Linux
实时操作系统: RTOS (Real-Time Operating System, 程序对时间要求十分严格: 计算的正确性不仅取决于程序的逻辑正确性,更取决于结果产生的时间)
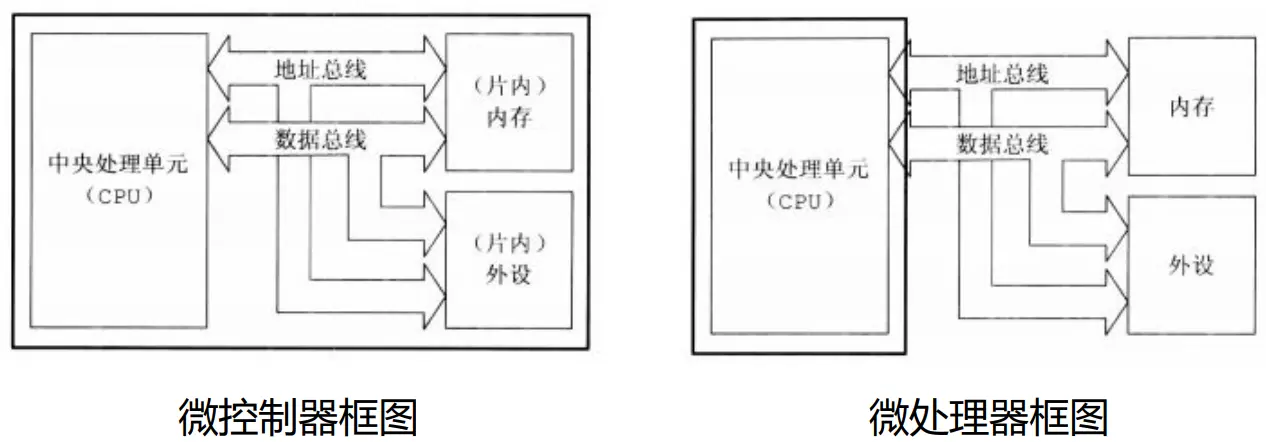
第二讲 嵌入式系统基础 体系结构-存储器组织 冯诺依曼体系结构
冯诺依曼体系理论
要点
程序指令存储器和数据存储器共用同一存储器,统一编址;程序指令和数据的宽度相同
哈佛体系结构
程序指令存储器和数据存储器使用两个独立的存储器,实现并行处理;
使用独立的两条总线,用于CPU与两个存储器进行通信
基本概念
CPU 字长: 微处理器一次执行处理的数据宽度
指令集: CPU 所能执行的所有指令的集合
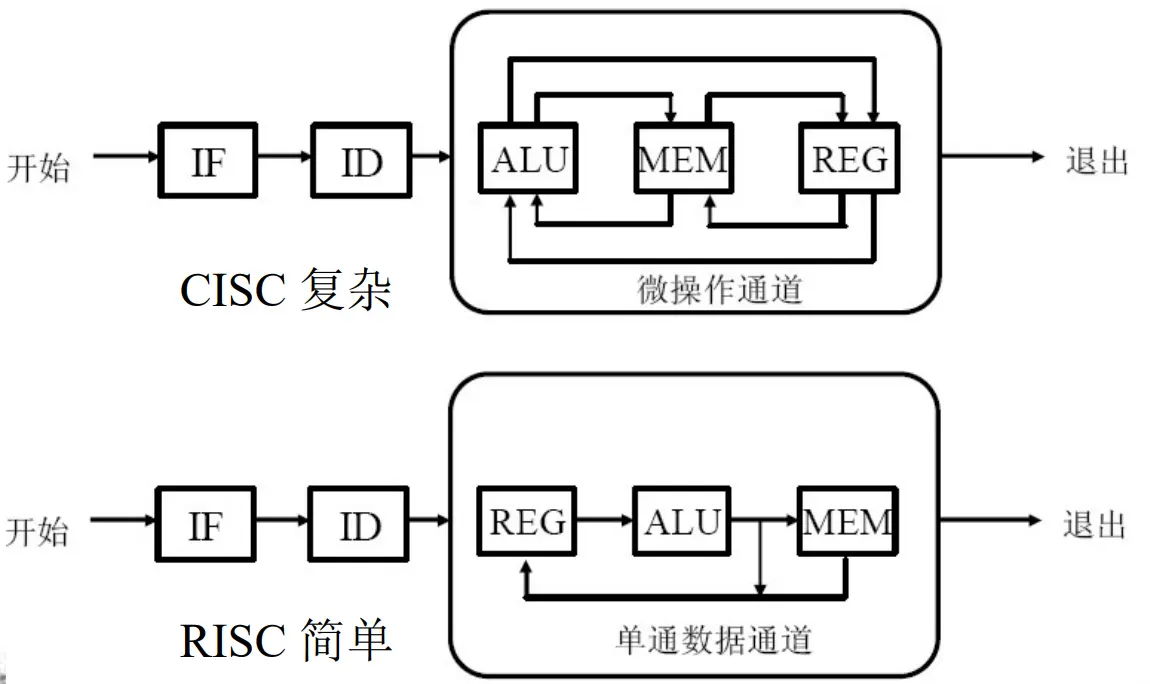
复杂指令集(CISC, Complex Instruction Set Computer)
具有大量指令和寻址方式
大多数程序只使用少量的指令就能够运行
精简指令集(RISC, Reduced Instruction Set Computer)
特点对比
RISC指令格式和长度固定,指令类型少,功能简单,寻址方式少,采用规则的硬布线逻辑(组合逻辑型)
CISC使用微码ROM进行指令译码(存储逻辑型)
RICS大多数指令单周期运行,分开的Load/Store结构的存取指令,固定指令格式
CISC强调硬件的复杂性,RISC注重编译器的复杂性
数据通道对比(RISC的任何运算只能在REG上执行,ALU的数据来源只能是REG,提高执行效率,对比CISC有数量级上的改善)
多任务程序结构 前后台程序结构
注:前后台是两种服务模式,前台对接时间严格事件,通过中断方式进行响应;后台对接时间不严格事件,分配时间片轮询处理每个任务
事件触发结构
状态机:实际上是有限状态机,类比马尔可夫决策
事件查询:(在状态中判断事件)主体是某一特定状态,决策是采取的不同事件,结果是执行不同功能,迁移到新状态
事件触发:(在事件中判断状态)主体是某一特定事件,决策是执行的不同动作,依据是当前的状态,结果是执行不同功能,迁移到新状态
操作系统
第三讲 ARM 基本编程模型
ARM=Advanced RISC Machines
ARM处理器特点
Load/Store 体系结构
16位/32位双指令集
3地址指令格式
Thumb 技术 开发背景
RISC代码密度低,需要比较大的存储器空间(RISC指令简单,完成同一个功能需要多条指令,因此需要更大的存储器空间)
需要32位RISC处理器的性能和16位CISC处理器的代码密度(32位RISC的性能, 16位CISC的代码密度)
Thumb 概述
技术概述
16位的指令长度
32位的执行效率
拥有2套独立的指令集
ARM处理器工作状态 ARM状态(ARM指令集)
Thumb状态(Thumb指令集)
状态切换
两个指令集均有切换处理器状态的指令
开始执行代码时处于ARM状态;异常处理时也处于ARM状态;异常处理返回时,可以返回到Thumb状态
运行模式
特权模式:除了用户模式外的其他模式
异常模式:除了用户模式、系统模式外的其他模式
功能说明
系统模式运行特权操作系统任务(与用户模式有完全相同的寄存器组)
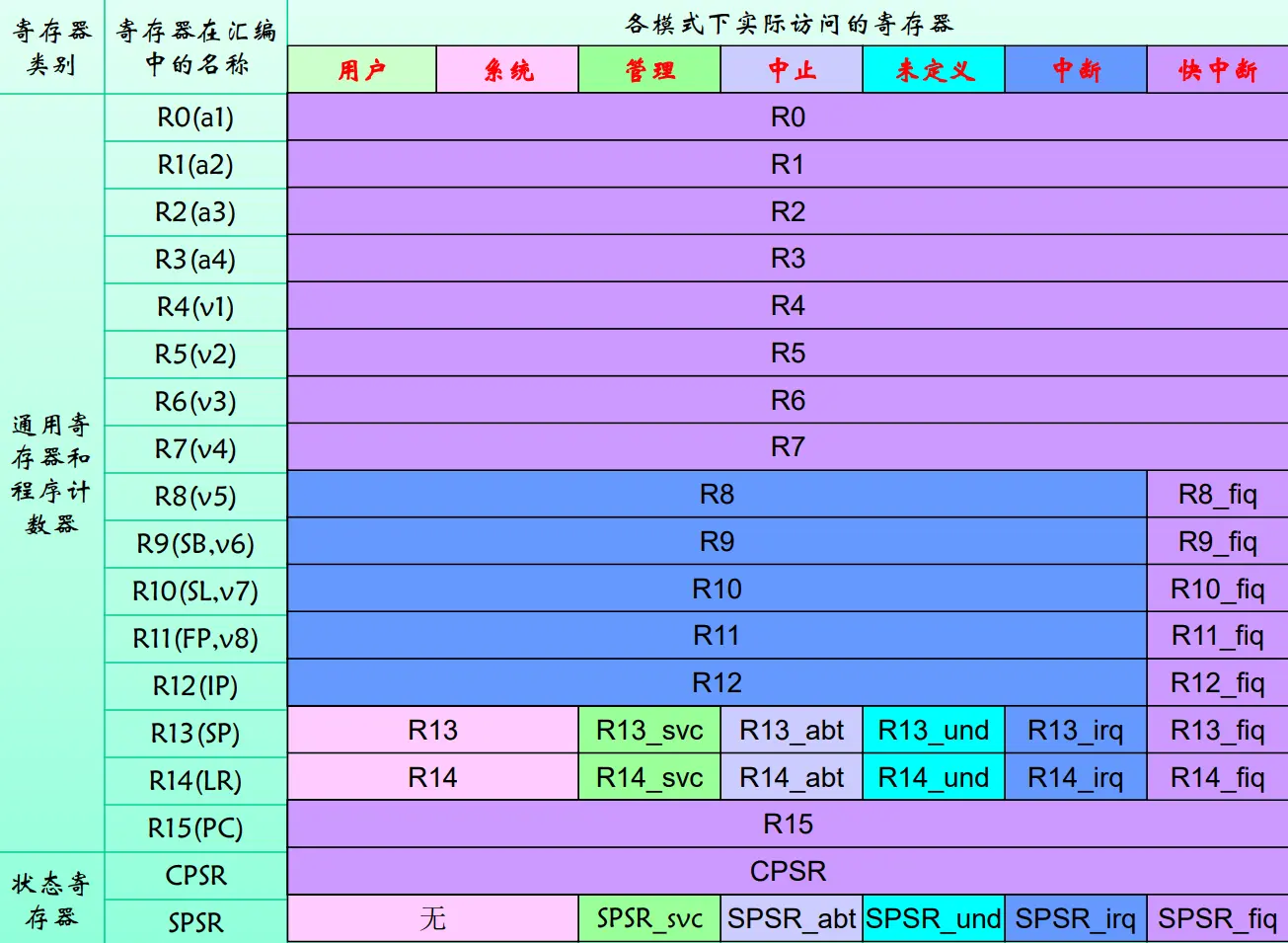
寄存器组织 ARM有37个32位长的寄存器:
1个PC(Program Counter), 30个通用寄存器, 1个CPSR(Current Program Status Register), 1个SPSR(Saved Program Status Register)
31个通用32位寄存器,6个状态寄存器
寄存器功能说明
R0$\sim$R13: 保存数据/地址值的通用寄存器,无特殊用途
R0$\sim$R7: 未分组寄存器,是所有处理器模式对应的通用寄存器,无特殊处理模式
R8$\sim$R12: 一个分组用于除FIQ模式之外的所有寄存器模式,另一组用于FIQ模式,目的:发生FIQ中断时,可以加速FIQ的处理速度,解释:专门为FIQ中断保留一组特定寄存器,能够保证在发生FIQ中断时,没有其他模式占用这一分组的寄存器(数据占用,处理器只能处于一个模式),可以使得中断处理更加迅速,因此也称为快中断模式
R13$\sim$R14: 有6个分组的寄存器,一个用于用户与系统模式,其余5个分别用于5中异常模式,解释:寄存器设置也同理,异常模式下,每当发生特定异常时,处理器需要进行异常处理,需要保证存在相应的寄存器能够为之提供服务,而不至于被其他模式所占用
R13: 堆栈指针寄存器,常作为堆栈指针(SP)
不严谨解释: 用户和系统模式共用同一R13,存放程序的指令代码以及其他数据;异常模式具有自己独立的物理寄存器R13:当程序进入不同的异常模式时,可以将需要保护的寄存器放入对应的R13所指向的堆栈中,当程序从异常模式返回时,则从对应的堆栈中恢复,
初始化要求:需要初始化每种模式下的R13
R14: 链接寄存器(LR),模式本身的R14用于保存子程序返回地址;进入异常模式时对应的R14用于保存异常返回地址
子程序调用返回:调用子程序时,指令先将下一条指令的PC值拷贝到R14,执行完子程序后,再将R14的值拷贝到PC,从而实现子程序的返回
异常处理的返回
R15: 程序计数器(PC),指向正在取指的地址
ARM状态下,位[1:0]为0,位[31:2]保存PC
Thumb状态下,位[0]为0,位[31:1]保存PC
ARM体系结构采用多级流水线技术,使得PC值为当前指令的地址值加8个字节
CPSR、SPSR: 程序状态寄存器,程序状态保存寄存器,SPSR仅在异常模式下能够被访问: 进入异常模式时,SPSR保存CPSR的值,异常返回时,通过SPSR的值恢复CPSR的值
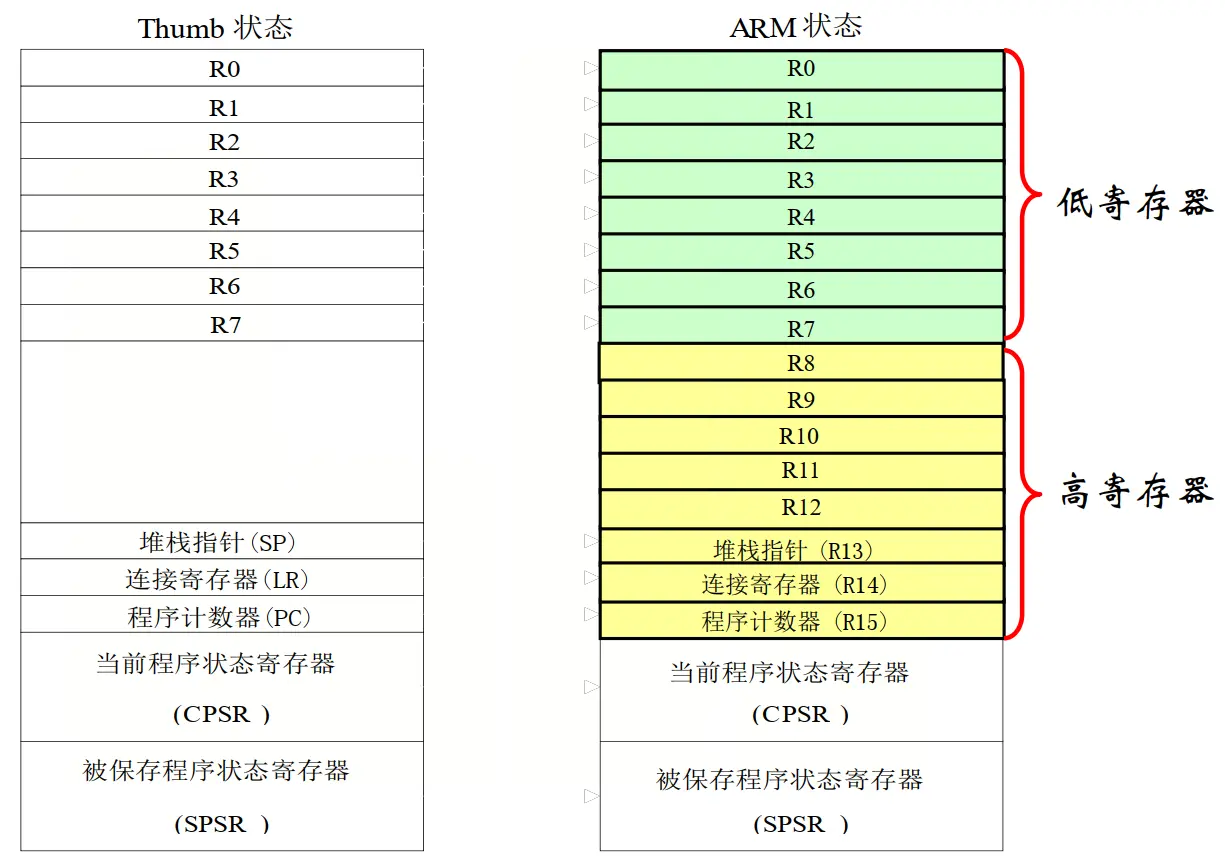
Thumb 状态下的寄存器 可以直接访问的寄存器: 8个通用寄存器R0$\sim$R7,程序计数器(PC),堆栈指针(SP),链接寄存器(LR),程序状态寄存器(CPSR),程序状态保存寄存器(SPSR)
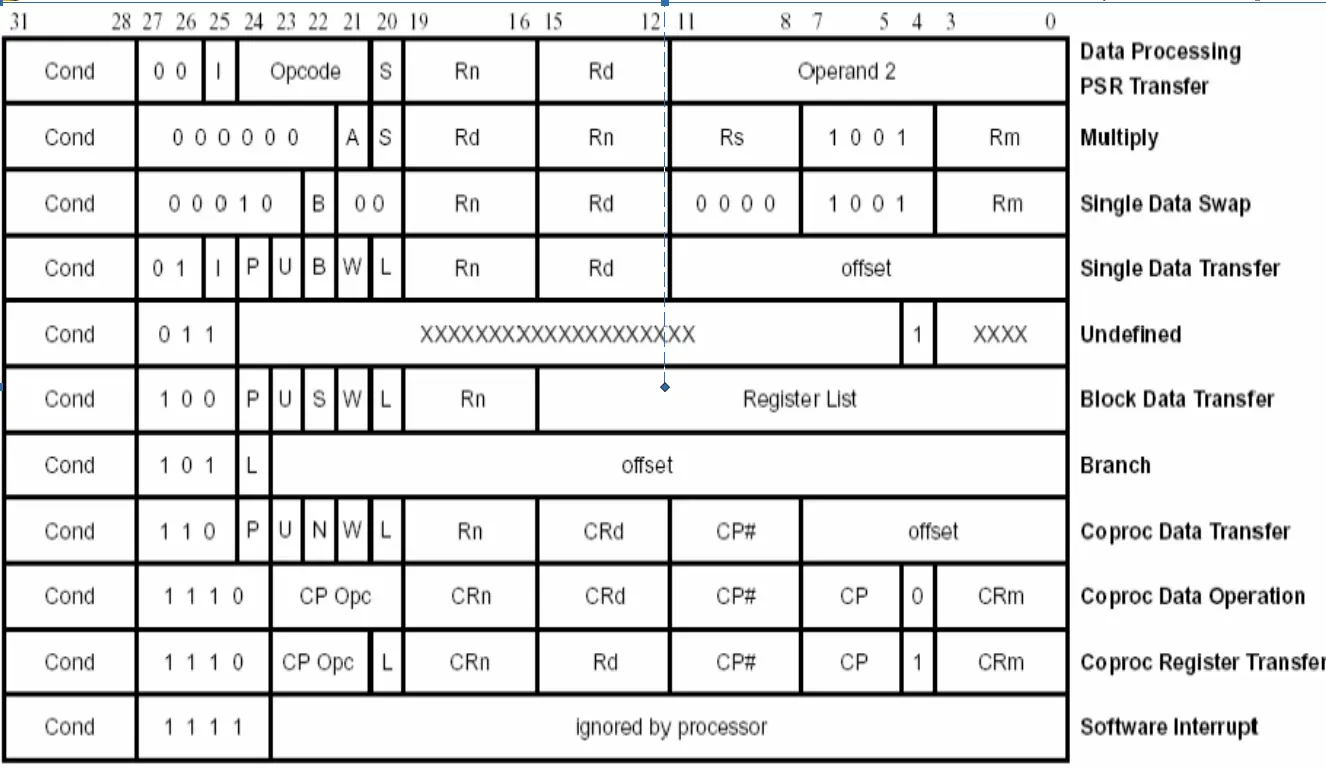
第四讲 ARM 指令系统 Load/Store 结构
所有操作数都存储在通用寄存器中
图解: MEM $\rightarrow$ REG $\rightarrow$ ALU $\rightarrow$ MEM
ARM 指令
指令分类:数据处理指令,Load/Store 指令,跳转指令,CPSR处理指令,异常产生指令,协处理器指令;
特殊指令:CPSR 处理指令
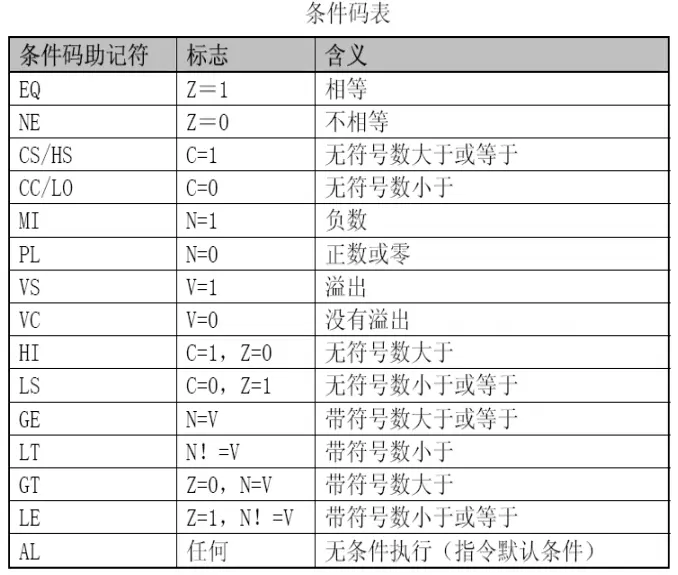
ARM 状态下,指令根据 CPSR 中条件码状态和指令条件域条件执行
嵌入式微处理器指令集:强调指令的灵活性,对称性,简单性
指令编码说明:
bit $12\sim15$: 4 bits 编码表示 $16$ 个通用寄存器
bit $28\sim31$: 指令条件码占据指令的高 $4$ bits, 并且条件编码 “1111” 为系统保留
ARM 寻址方式
立即寻址: 操作数(立即数)包含在指令的 $32$ 位编码中
指令说明
只有第二源操作数可用立即数
立即数以 “#” 为前缀,”#” 后加 “0x” 或 “&” 表示十六进制,”0b” 表示二进制,”0d” 或缺省表示十进制
Example
ADD R$0$, R$0$, #$1$
AND R$3$, R$4$, #$0$xFF
寄存器寻址: 操作数在寄存器中,指令地址码字段编码寄存器编号
Example
MOV R$1$, R$2$ ; R$1$ = (R$2$)
SUB R$0$, R$1$, R$2$ ; R$0$ = (R$1$) - (R$2$)
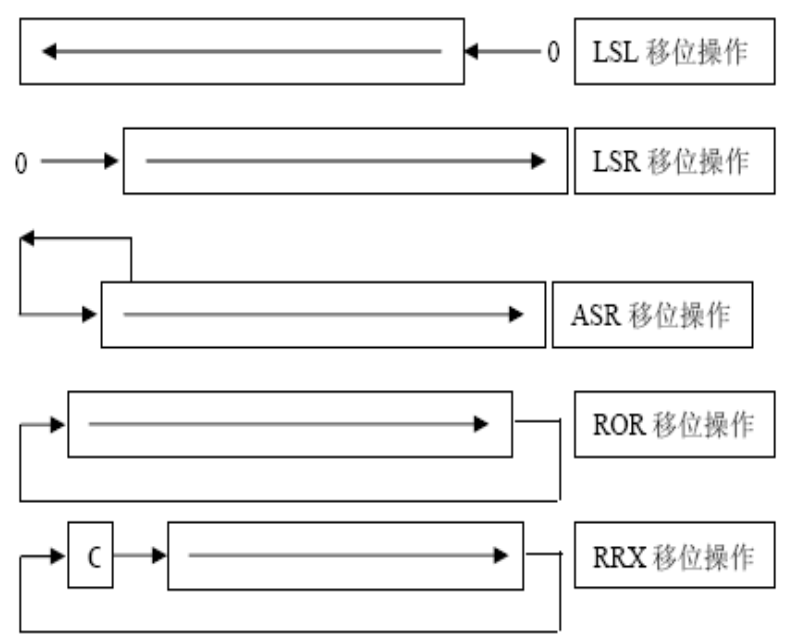
寄存器移位寻址: ARM 指令集特有寻址方式,主要为了增强精简指令的执行效率
指令说明
ARM 移位寻址中,在取操作数送往ALU过程中,就已经在总线上完成了移位运算操作
Example
MOV R$0$, R$2$, LSL #3 ; R$0$ = (R$2$) << 3
ANDS R$1$, R$2$, LSL R$3$ ; R$1$ = (R$1$) & (R$2$) << (R$3$)
LSL(Logical Shift Left)
LSR(Logical Shift Right)
ASL(Arithmetic Shift Left)
ASR(Arithmetic Shift Right)
ROR(Rotate Right)
RRX(Rotate Right Extended by 1 Place)
基址寻址: 存储器地址在寄存器中
指令说明
Example
LDR R$0$, [R$1$]
STR R$0$, [R$1$]
变址寻址: 基址寄存器+地址偏移量
地址偏移量
立即数
控制位 U=$1$时加偏移量,U=$0$时减偏移量
偏移量占 $12$ Bit(立即数)
Example:
LDR R$0$, [R$1$, #4]
LDR R$0$, [R$1$, #-4]
寄存器
控制位 U=$1$时加索引寄存器值,U=$0$时减索引寄存器值
Example:
LDR R$0$, [R$1$, R$2$]
LDR R$0$, [R$1$, -R$2$]
寄存器及移位常数
Example:
LDR R$0$, [R$1$, R$2$, LSL #2]
前变址模式
LDR R$0$, [R$1$, #$4$] ; R$0$ = Mem$32$[R$1$+$4$]
自动变址模式(事先更新方式)
LDR R$0$, [R$1$, #$4$]! ; R$0$ = Mem$32$[R$1$+$4$], R$1$ = R$1$ + $4$
后变址模式(事后更新方式)
LDR R$0$, [R$1$], #$4$ ; R$0$ = Mem$32$[R$1$], R$1$ = R$1$ + $4$
3种地址偏移格式与3种变址模式,可以组合出9种类型的变址寻址方式。
相对寻址: 基址寄存器是程序计数器 PC
1 2 3 4 BL SUBR SUBR .... MOV PC , R14
块拷贝寻址
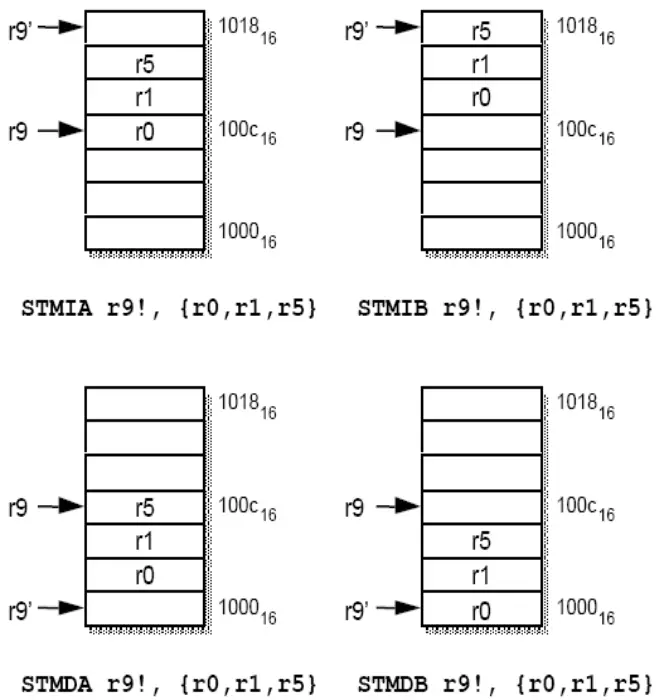
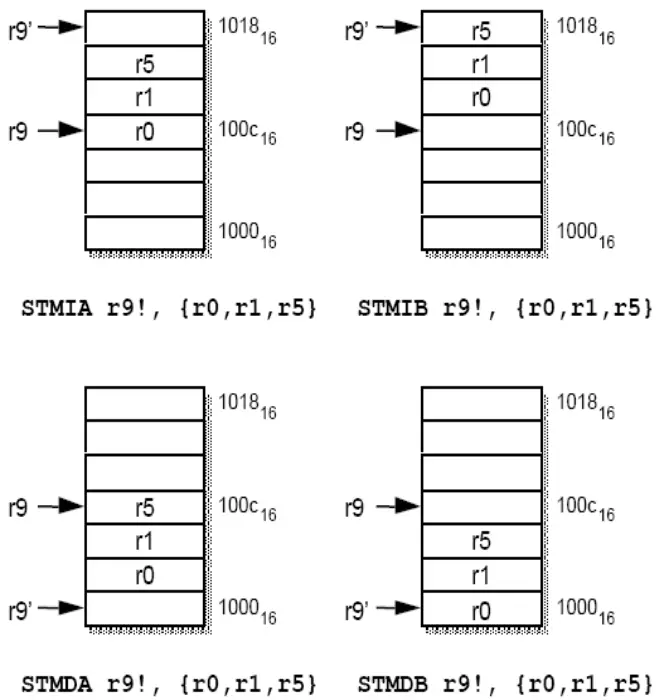
多寄存器传送指令 LDM/STM 的寻址方式
寄存器组可以是 $16$ 个通用寄存器的任意子集
地址增长顺序: IA(Increment After), IB(Increment Before), DA(Decrement After), DB(Decrement Before)
Example
堆栈寻址
堆栈形式
满递增(指令:LDMFA, STMFA)
空递增(指令:LDMEA, STMEA)
满递减(指令:LDMFD, STMFD)
空递减(指令:LDMFD, STMFD)
Example
ARM指令中的堆栈
STMFD SP!, {R$1$-R$7$, LR}
LDMFD SP!, {R$1$-R$7$, LR}
Thumb指令中的堆栈
PUSH {R1-R7, LR}
POP {R1-R7, PC}
ARM 指令集概述 数据处理指令
主要完成寄存器 中数据的算术和逻辑运算操作
数据宽度:所有操作数都是 $32$ 位宽度
Load/Store 指令 该类指令用于寄存器与内存中数据传送,因为ALU的数据来源只能是寄存器,寄存器中数据要提前从内存中获取。
单寄存器存取指令(LDR/STR)(Load Register/Store Register)
加载/存储字/半字/字节(32位对齐/16位对齐/8位对齐)
多寄存器存取指令(LDM/STM)(Load Multiple Registers/Store Multiple Registers)
存储器与寄存器交换指令SWP
杂项指令 第五讲 ARM 指令详细介绍
数据处理指令 数据传送指令(2条)
MOV
MVN(Move Not)
指令格式: MVN{条件}{S} 目的寄存器, 源操作数
源操作数: 寄存器、被移位的寄存器、立即数
指令说明: 将源操作数按位取反传送到目的寄存器,实现逻辑非
S: 存在S时表示更新CPSR中条件标志位
Example
算术运算指令(6条)
三地址指令格式
ADD
指令格式: ADD{条件}{S} 目的寄存器, 操作数1, 操作数2
指令说明: 目的寄存器 = 操作数1 + 操作数2
操作数1: 寄存器
操作数2: 寄存器、被移位的寄存器、立即数
Example
ADD R0, R1, R2
ADD R0, R1, #100
ADD R0, R1, R2 LSL #1
ADC
指令格式: ADC{条件}{S} 目的寄存器, 操作数1, 操作数2
指令说明: 目的寄存器 = 操作数1 + 操作数2 + CF
操作数1: 寄存器
操作数2: 寄存器、被移位的寄存器、立即数
Example: 128位数加法
; 128Num1: R7-R4, 128Num2: R11-R8, 128Sum: R3-R0
ADDS R0, R4, R8 ; 加低位的字
ADCS R1, R5, R9 ; 加第二个字,带进位
ADCS R2, R6, R10 ; 加第三个字,带进位
ADC R3, R7, R11 ; 加高8位,带进位
SUB
指令格式: SUB{条件}{S} 目的寄存器, 操作数1, 操作数2
指令说明: 目的寄存器 = 操作数1 - 操作数2
操作数1: 寄存器
操作数2: 寄存器、被移位的寄存器、立即数
Example:
SUB R0, R1, R2
SUB R0, R1, #256
SUB R0, R1, R2 LSL #1
SBC
指令格式: SBC{条件}{S} 目的寄存器, 操作数1, 操作数2
指令说明: 目的寄存器 = 操作数1 - 操作数2 - $\overline{CF}$
操作数1: 寄存器
操作数2: 寄存器、被移位的寄存器、立即数
Example: 64位数减法
; 64Num1: R1-R0, 64Num2: R3-R2, 64Sub: R1-R0
SUBS R0, R0, R2 ; 加低位的字
SBC R1, R1, R3 ; 加第二个字,带进位
注解: 假设R3-R0为4位寄存器,做减法: 46H-24H;
6H-4H = [6H]补 + [-4H]补 = 0110B + 1100B = 0010B $\Rightarrow$ R0 = 2H with CF = 1 (数据有溢出)
4H-2H-$\overline{CF}$ = [4H]补 + [-2H]补 = 0100B + 1110B = 0010B $\Rightarrow$ R1 = 2H with CF = 1 (数据有溢出)
RSB(Reverse Subtract)
指令格式: RSB{条件}{S} 目的寄存器, 操作数1, 操作数2
指令说明: 目的寄存器 = 操作数2 - 操作数1
操作数1: 寄存器
操作数2: 寄存器、被移位的寄存器、立即数
Example:
RSB R0, R1, R2
RSB R0, R1, #256
RSB R0, R1, R2 LSL #1
RSC
指令格式: RSC{条件}{S} 目的寄存器, 操作数1, 操作数2
指令说明: 目的寄存器 = 操作数2 - 操作数1 - CF
操作数1: 寄存器
操作数2: 寄存器、被移位的寄存器、立即数
Example: 64位数减法
; 64Num1: R1-R0, 64Num2: 0, 64Sub: R3-R2
RSBS R2, R0, #0
RSC R3, R1, #0
逻辑运算指令(4条)
AND
指令格式: AND{条件}{S} 目的寄存器, 操作数1, 操作数2
指令说明: 目的寄存器 = 操作数1 & 操作数2
操作数1: 寄存器
操作数2: 寄存器、被移位的寄存器、立即数
Example: 屏蔽操作数1的某些位
ORR
指令格式: ORR{条件}{S} 目的寄存器, 操作数1, 操作数2
指令说明: 目的寄存器 = 操作数1 | 操作数2
操作数1: 寄存器
操作数2: 寄存器、被移位的寄存器、立即数
Example: 设置操作数1的某些位
EOR
指令格式: EOR{条件}{S} 目的寄存器, 操作数1, 操作数2
指令说明: 目的寄存器 = 操作数1 ^ 操作数2
操作数1: 寄存器
操作数2: 寄存器、被移位的寄存器、立即数
Example: 反转操作数1的某些位
BIC
指令格式: BIC{条件}{S} 目的寄存器, 操作数1, 操作数2
指令说明: 清除操作数1的某些位,操作数2作为操作数1的掩码,如果操作数2置位,则清除操作数1对应位
操作数1: 寄存器
操作数2: 寄存器、被移位的寄存器、立即数
Example:
比较指令(2条)
CMP
指令格式: CMP{条件} 操作数1, 操作数2
指令说明: 操作数1-操作数2 =操作数1+[-操作数2]补码=操作数1+[操作数2]求补,不存储结果,只影响CPSR中标志位
操作数1: 寄存器
操作数2: 寄存器、立即数
Example:
CMN
指令格式: CMN{条件} 操作数1, 操作数2
指令说明: 操作数1-[操作数2]求补=操作数1+[-[操作数2]求补]补码=操作数1+[[操作数2]求补]求补=操作数1+操作数2 ,不存储结果,只影响CPSR中标志位
操作数1: 寄存器
操作数2: 寄存器、立即数
Example:
测试指令(2条)
TST
指令格式: TST{条件} 操作数1, 操作数2
指令说明: 操作数1 & 操作数2,不存储结果,只影响CPSR中标志位(ZF); 操作数2一般作为位掩码
操作数1: 寄存器
操作数2: 寄存器、立即数
Example:
TST R1, #1 ; 测试最低位是否为1
TST R1, #0xffe
TEQ
指令格式: TEQ{条件} 操作数1, 操作数2
指令说明: 操作数1 ^ 操作数2,不存储结果,只影响CPSR中标志位(ZF); 通常用于比较操作数1和操作数2是否相等
操作数1: 寄存器
操作数2: 寄存器、立即数
Example:
乘法指令(6条)
MUL(32位有符号或无符号乘法)
指令格式: MUL{条件}{S} 目的寄存器, 操作数1, 操作数2
指令说明: 目的寄存器 = [操作数1 * 操作数2][31…0],影响CPSR中标志位
操作数1: 寄存器
操作数2: 寄存器
Example:
MUL R0, R1, R2
MULS R0, R1, R2
MLA(32位有符号或无符号乘加法, Mulliply Add)
指令格式: MLA{条件}{S} 目的寄存器, 操作数1, 操作数2, 操作数3
指令说明: 目的寄存器 = [操作数1 * 操作数2 + 操作数3][31…0],影响CPSR中标志位
操作数1: 寄存器
操作数2: 寄存器
Example:
MLA R0, R1, R2, R3
MLAS R0, R1, R2, R3
SMULL(64位有符号数乘法, Signed Mulliply Long)
指令格式: SMULL{条件}{S} 目的寄存器Low, 目的寄存器High, 操作数1, 操作数2
指令说明: 目的寄存器 = [操作数1 * 操作数2][63…0],影响CPSR中标志位
操作数1: 32位寄存器
操作数2: 32位寄存器
Example:
SMULL R0, R1, R2, R3 ; R0(Low32) = (R2R3)(Low32), R1(High32) = (R2 R3)(High32)
SMULLS R0, R1, R2, R3
SMLAL(64位有符号数乘加法, Signed Mulliply ADD Long)
指令格式: SMLAL{条件}{S} 目的寄存器Low, 目的寄存器High, 操作数1, 操作数2
指令说明: 目的寄存器 = [操作数1 * 操作数2 + 目的寄存器][63…0],影响CPSR中标志位
操作数1: 32位寄存器
操作数2: 32位寄存器
Example:
SMLAL R0, R1, R2, R3 ; R0(Low32) = (R2R3)(Low32) + R0(Low32), R1(High32) = (R2 R3)(High32) + R1(High32)
SMLALS R0, R1, R2, R3
UMULL(64位无符号数乘法, Unsigned Mulliply Long)
指令格式: UMULL{条件}{S} 目的寄存器Low, 目的寄存器High, 操作数1, 操作数2
指令说明: 目的寄存器 = [操作数1 * 操作数2][63…0],影响CPSR中标志位
操作数1: 32位寄存器
操作数2: 32位寄存器
Example:
UMULL R0, R1, R2, R3 ; R0(Low32) = (R2R3)(Low32), R1(High32) = (R2 R3)(High32)
UMULLS R0, R1, R2, R3
UMLAL(64位无符号数乘加法, Unsigned Mulliply ADD Long)
指令格式: UMLAL{条件}{S} 目的寄存器Low, 目的寄存器High, 操作数1, 操作数2
指令说明: 目的寄存器 = [操作数1 * 操作数2 + 目的寄存器][63…0],影响CPSR中标志位
操作数1: 32位寄存器
操作数2: 32位寄存器
Example:
UMLAL R0, R1, R2, R3 ; R0(Low32) = (R2R3)(Low32) + R0(Low32), R1(High32) = (R2 R3)(High32) + R1(High32)
UMLALS R0, R1, R2, R3
Load/Store指令
ARM中用于在寄存器和存储器之间传送数据的指令
单寄存器存取指令(6条)
LDR(字数据加载指令)
指令格式: LDR{条件} 目的寄存器, <存储器地址>
指令说明: 目的寄存器 = Mem[Address]——32位字数据
Example:
LDR R0, [R1] ; R0 = Mem[R1]
LDR R0, [R1, R2] ; R0 = Mem[R1+R2]
LDR R0, [R1, #4] ; R0 = Mem[R1+4]
LDR R0, [R1, R2]! ; R0 = Mem[R1+R2], R1 = R1 + R2
LDRB(字节数据加载指令)
指令格式: LDR{条件}B 目的寄存器, <存储器地址>
指令说明: 目的寄存器[7…0] = Mem[Address]——8位字节数据, 目的寄存器[31…8] = 0
Example:
LDRB R0, [R1] ; R0 = Mem[R1]
LDRB R0, [R1, #8] ; R0 = Mem[R1+8]
LDRH(半字数据加载指令)
指令格式: LDR{条件}H 目的寄存器, <存储器地址>
指令说明: 目的寄存器[15…0] = Mem[Address]——16位字节数据, 目的寄存器[31…16] = 0
Example:
LDRB R0, [R1] ; R0 = Mem[R1]
LDRB R0, [R1, #8] ; R0 = Mem[R1+8]
STR(字数据存储指令)
指令格式: STR{条件} 源寄存器, <存储器地址>
指令说明: Mem[Address] = 源寄存器——32位字数据
Example:
STR R0, [R1], #8 ; Mem[R1] = R0, R1 = R1 + 8
STR R0, [R1, #4] ; Mem[R1+4] = R0
STR R0, [R1, R2]! ; Mem[R1+R2] = R0, R1 = R1 + R2
STRB(字节数据存储指令)
指令格式: STR{条件}B 源寄存器, <存储器地址>
指令说明: Mem[Address] = 源寄存器Low8——8位字节数据
Example:
STRB R0, [R1] ; Mem[R1] = R0(Low8)
STRB R0, [R1, #8] ; Mem[R1+8] = R0(Low8)
STRH(半字数据存储指令)
指令格式: STR{条件}H 源寄存器, <存储器地址>
指令说明: Mem[Address] = 源寄存器Low16——16位半字数据
Example:
STRH R0, [R1] ; Mem[R1] = R0(Low16)
STRH R0, [R1, #8] ; Mem[R1+8] = R0(Low16)
Check Point: Load/Store指令的基址寻址于变址变址
多寄存器存取指令(2条) ARM中支持的批量数据加载/存储指令可以一次在一片连续的存储器单元和多个寄存器之间传送数据,通常用于堆栈操作
STM(批量数据存储指令)
指令格式: STM{条件}{类型} 基址寄存器{!}, 寄存器列表{^}
指令说明: 多个寄存器中字数据传送到基址寄存器指向的连续存储器单元中
类型——地址增长顺序: IA(Increment After), IB(Increment Before), DA(Decrement After), DB(Decrement Before)
Example:
LDM(批量数据加载指令)
指令格式: LDM{条件}{类型} 基址寄存器{!}, 寄存器列表{^}
指令说明: 基址寄存器指向的连续存储器单元中字数据传送到多个寄存器中
Example:
存储器和寄存器交换指令(2条)
主要用于实现信号量操作,信号量用于进程的同步与互斥
SWP
指令格式: SWP{条件} 目的寄存器, 源寄存器1, [源寄存器2]
指令说明: 目的寄存器=Mem[源寄存器2],Mem[源寄存器2] = 源寄存器1
Example: 寄存器和存储器交换
跳转指令 ARM程序跳转概述
ARM程序跳转
B(Branch) 分支跳转指令,根据条件进行分支跳转
B{条件} 目标地址
不加条件时,表示无条件跳转指令
BL(Branch with Link) 分支链接指令
BL{条件} 目标地址
将下一条指令的地址拷贝到链接寄存器(R14/LR)中,然后跳转到指定的地址运行程序
BX(Branch and eXchange) 分支交换指令
BX{条件} 目标地址
带状态切换的跳转指令,具体状态有目标寄存器最低位决定
BLX(Branch with Link and eXchange) 分支链接交换指令
程序状态寄存器访问指令 用于在程序状态寄存器(CPSR/SPSR)和通用寄存器之间传送数据
MRS
指令格式: MRS{条件} 通用寄存器, 程序状态寄存器
指令说明: 状态寄存器的内容读取到通用寄存器, Rn$\rightarrow$ CPSR/SPSR
Example:
临时保存程序状态寄存器的内容
异常处理或进程切换时,先读再存程序状态寄存器中的值
MSR
指令格式: MSR{条件} 程序状态寄存器_<域>, 操作数
指令说明: 将操作数的内容传送到状态寄存器的特定域中,操作数可以为通用寄存器或立即数
域:对32位程序状态字寄存器的划分,分为4个8位域
c位[7:0]为控制位域, 表示为c
x位[15:8]为扩展位域, 表示为x
s位[23:16]为状态位域, 表示为s
f位[31:24]为条件标志位域, 表示为f
Example:
MSR CPSR, R0
MSR CPSR_c, R0
异常产生指令
协处理器指令 第六讲 ARM汇编 ARM汇编语言源程序一般由ARM指令、伪操作(包括伪指令)和宏指令组成;其中伪操作(包括伪指令)是由汇编器在对源程序汇编期间由汇编程序处理的。
伪操作 符号定义伪操作 用于定义ARM汇编程序中的变量,对变量赋值和寄存器重命名
定义全局变量(GBLA(GloBaL Arithmetic), GBLL(GloBaL Logical), GBLS(GloBaL String))
指令格式: GBLA(GBLL/GBLS) 全局变量名
指令说明: GBLA算术, GBLL逻辑, GBLS字符串
定义ARM程序中全局变量并初始化为0
Example:
GBLA Test1
Test1 SETA 0xaa
GBLL Test2
Test2 SETL {TRUE}
GBLS Test3
Test3 SETS “Testing”
定义局部变量(LCLA(LoCaL Arithmetic), LCLL(LoCaL Logical), LCLS(LoCaL String))
指令格式: LCLA(LCLL/LCLS) 局部变量名
指令说明: LCLA算术, LCLL逻辑, LCLS字符串
定义ARM程序中局部变量并初始化为0
Example:
LCLA Test1
Test1 SETA 0xaa
LCLL Test2
Test2 SETL {TRUE}
LCLS Test3
Test3 SETS “Testing”
对变量进行赋值(SETA(SET Arithmetic), SETL(SET Logical), SETS(SET String))
指令格式: 变量名 SETA(SETL/SETS) 表达式
指令说明: 为已定义过的 全局变量或局部变量进行赋值
Example:
LCLA Test1
Test1 SETA 0xaa
LCLL Test2
Test2 SETL {TRUE}
命名通用寄存器列表(RLIST(Register List))
指令格式: 名称 RLIST {寄存器列表}
指令说明: 用于对一个通用寄存器列表定义名称,列表中寄存器访问次序为寄存器的编号由低到高
Example:
Reglist RLIST {R0-R5, R8, R10}
数据定义伪操作 汇编控制伪操作
控制汇编程序的执行流程
IF…ELSE…ENDIF
WHILE…WEND
MACRO…MEND(Macro)
MEXIT
信息报告伪操作
ASSERT
指令格式: ASSERT Logical_Expression
指令说明: 断言表达式成立否则报错,并且该伪操作在第二次扫描汇编程序中判断
Example:
INFO
指令格式: INFO numeric_expr, string_expr
指令说明: 该伪操作在第一次或第二次扫描时报告诊断信息
参数说明: numeric_expr = 0 第一遍扫描时报告,否则第二遍时;string_expr: 诊断信息
Example:
其他伪操作
AREA
指令格式: AREA 段名, 属性1, 属性2, …
指令说明: CODE属性(代码段),DATA属性(数据段),READONLY属性,READWRITE属性
Example:
AREA Init,CODE,READONLY
…
END
CODE
指令格式: CODE16/CODE32
指令说明: 通过CODE16伪操作通知编译器其后指令为16位的Thumb指令;CODE32通知编译器其后指令为32位的ARM指令;以此进行ARM的状态切换
ENTRY
指令格式: ENTRY
指令说明: ENTRY伪操作用于指定汇编程序入口点; 在一个完整的汇编程序中至少要有一个ENTRY
Example:
AREA Init,CODE,READONLY
ENTRY
END
指令格式: END
指令说明: END伪操作用于通知编译器已经到了源程序的结尾
Example:
AREA Init,CODE,READONLY
…
END
EQU
指令格式: 名称 EQU 表达式 {,类型}
指令说明: EQU伪操作用于为程序中的标号、数字常量和寄存器的值等定义一个字符名称;可以用’*’代替
Example:
Test EQU 50
Addr * 0x55,CODE32 ; 定义Addr的值为0x55, 且该处为32位的ARM指令(类型)
EXPORT/GLOBAL
指令格式: EXPORT 标号
指令说明: 用于在程序中声明一个全局的标号
Example: 1 2 3 4 AREA Init CODE ,READONLY EXPORT Test ... END
IMPORT
指令格式: IMPORT 标号
指令说明: 用于通知编译器要使用的标号在其他的源文件中定义,但要在当前源文件中引用; 如果没有引用,该标号实际上会被加入到当前源文件中
Example: 1 2 3 4 AREA Init CODE ,READONLY IMPORT Main ... END
EXTERN
指令格式: EXTERN 标号
指令说明: 用于通知编译器要使用的标号在其他的源文件中定义,但要在当前源文件中引用; 如果没有引用,该标号实际上不会被加入到当前源文件中
GET
指令格式: GET 文件名
指令说明: GET伪操作用于将一个源文件包含到当前的源文件中,并将被包含的源文件在当前位置进行汇编处
可以使用INCLUDE代替GET
ARM语言伪指令 伪指令不是真正的ARM指令,在汇编过程中会被替换成对应的ARM指令或指令序列
ADR(AdDRess)
指令格式: ADR {cond} register, 标号
指令说明: 将基于PC的地址值(程序标号)或基于寄存器的地址值加载到寄存器中
Example: 1 2 3 start MOV R0 , #0 ADR R1 , start => SUB R1 , pc , #0xC
ADRL(AdDRess Large)
指令格式: ADRL {cond} register, 标号
指令说明: 将基于PC的地址值(程序标号)或基于寄存器的地址值加载到寄存器中,可被替换成两条合适的指令,所以加载的地址范围更大
Example: 1 2 3 4 start MOV R0 , #0 ADRL R1 , start + 60000 => ADD R1 , pc , 0xE800 => ADD R1 , R1 , 0x254
LDR(Load Register)
指令格式: LDR {cond} register, = expr 或 label-expr
指令说明: 可将任意一个32位常数或地址值加载到寄存器中
Example: 1 2 3 4 LDR R1 , =0xFF => MOV R1 , 0xFF LDR R1 , =0xFFF => LDR R1 , [PC , OFFSET_TO_LPOOL]
NOP(NO Operation)
指令格式: NOP
指令说明: 汇编时会被替换成一条无用指令, 不影响CPSR中的条件标志位
Example:
第七讲 ARM下的C编程 了解C运行时库 C运行时库(C Runtime Library)用于在C程序运行时提供支持的函数和例程集合,包含C语言所需的基本功能和支持:
ARM的C编译器支持ANSI C运行时库
ARM C运行时库以二进制形式提供
用户可以建立自己的运行时库
宏和函数的区别 宏:在C程序中定义的命名代码段。
编译器会将相关代码放到宏名出现的每一个地方,宏的代码在任何出现宏名的地方都会编译一次 ;使用宏时不需要保存/恢复上下文,也不必返回
在编译器预处理阶段会被直接展开到代码 中,编译时用宏内容替换宏调用位置,可能导致代码膨胀
代码简单 用宏
函数:
函数的代码只需要编译一次
在编译时定义,但实际执行发生在运行时 ,会有函数调用开销
代码复杂 用函数
三、什么是内嵌汇编
标识符:_ _asm:用于告诉编译器后面是汇编代码
内嵌汇编 1 2 3 4 5 6 7 8 9 10 void enable_IRQ (void ) { int temp; __asm { MRS tmp, CPSR BIC tmp, tmp, #0x80 MSR CPSR_c, tmp } }
_irq、volatile关键字的作用 _irq :使用该关键字声明的函数 可以被用作异常中断的中断处理程序,该函数通过将lr-4的值赋予PC寄存器,并将 SPSR的值赋予CPSR实现函数返回
volatile :用于声明变量 ,告诉编译器该变量可能在程序之外修改;编译时不能优化对volatile变量的操作;不能对volatile变量使用缓冲技术
汇编和 C 的混合编程 参数传递规则 :
参数个数可变的子程序参数传递规则:
参数不超过4个时,使用R0~R3来传递;
参数超过4个时,可以使用数据栈来传递
参数个数固定的子程序参数传递规则:
第一个整数参数,通过R0~R3来传递
其他参数通过数据栈来传递
有关浮点运算,需特别处理
子程序结果返回规则:
结果为一个32位整数时,可以通过寄存器R0返回
结果为一个64位整数时,可以通过寄存器R0和R1返回, 依次类推
ARM 异常响应过程
当异常中断发生时, 系统执行完当前指令后,跳转到相应的异常中断处理 程序处执行
执行完成后,程序返回到发生中断的指令的下一条指 令处执行
进入异常中断处理程序时要保存现场,返回时要恢复 现场
当异常发生时,处理器会把PC设置为一个特定的存储器地址
这一地址放在被称为向量表(vector table)的特定地址范围内
异常向量表通常放在存储地址的低端
第八讲 RISC-V&华为鲲鹏 指令集架构(ISA)和国内ISA生态
指令:是指处理器进行操作的最小单元(如算术/逻辑运算);
指令集:顾名思义是指一组指令的集合;
指令集架构:又称为“处理器架构”,不仅是指令的集合,还包括编程需要的硬件信息,如支持的数据类型、存储器、寄存器状态、寻址模式和寄存器模型等;
指令集架构(ISA, Instruction Set Architecture)才是区分不同CPU的标准;
微架构:处理器的具体硬件实现方案称为微架构;
常见指令集架构:x86(CISC) , SPARC, MIPS , Power(国产), Alpha(国产), ARC, ARM(RISC) , Intel
RISV-V的主要特征 RISC-V,是一种基于“精简指令集(RISC)”原则的指令集架构,它具有开源、重新设计(后发优势)、简单哲学、模块化指令集、指令集可扩展的特点。
华为鲲鹏
鲲鹏 920 使用的指令集架构是 ARM v8 64 位
鲲鹏 920 生产使用的制程是 7nm
相比于上一代的鲲鹏 916,鲲鹏 920 处理器的计算核数提升 1 倍,最多支持 64 核
第九讲 最小系统设计 嵌入式系统最小系统 CPU能够运行所需的模块有(最小系统):电源、时钟、复位、内存、调试接口(JTAG)
DC-DC 转换器的常见形式 线性稳压器、开关稳压器和充电泵
晶体和晶振 时钟一般由晶体振荡器提供,而晶体和晶振是构成晶体振荡器的两种方式:
晶体(无源)
封装内部只含有晶体, 没有内部电源
驱动电路由设计者提供
晶振(有源)
复位的基本功能
SRAM,DRAM,SDRAM和Flash
SRAM(静态RAM)
数据存入静态RAM后,只要电源维持不变 ,其中存储的数据就能够一直维持不变 , 不需要刷新操作
读写速度快 由触发器构成基本单元,接口简单
存储单元结构复杂,集成度较低 常常用作高速缓冲存储器 [读写速度快]
DRAM(动态RAM)
依靠电容存储 信息,需要不断刷新
读写速度慢 集成度高 ,成本低地址引脚少,地址总线采用多路技术,接口复杂
SDRAM(同步动态RAM)
SDRAM因为要同CPU和芯片组共享时钟,所以芯片组可以主动的在每个时钟的上升沿发给引脚控制命令
动态RAM加上同步特性[在每个时钟的上升沿发给引脚控制命令]
Nor Flash
芯片内执行 读速度快 (相比Nand Flash)写入与擦除速度很低
擦除按块进行 ,写入前必须先擦除带有SRAM接口,有足够的地址引脚来寻址,可以很容易地存取其内部的每一个字节
常用来存储代码
Nand Flash
NAND读和写操作按512字节的块 进行
写入与擦除速度比Nor Flash快 擦除按块进行 ,写入前必须先擦除NAND的擦除单元更小,相应的擦除电路更少
NAND器件使用复杂的I/O口来串行地存取数据
常用来存储数据
存储器映射 存储器映射到物理地址 , 通过将存储器按照物理地址划分为不同模块, 进行RAM, DRAM, SDRAM, FLASH等存储设计.
第十讲 外部设备及通信接口 常用外部接口 I/O(Input/Output)接口是一个微控制器必须具备的最基本的外设功能.
每个I/O口一般都对应了两个寄存器:
数据寄存器:数据寄存器的各位都直接引到芯片外部
控制寄存器:控制数据寄存器中每位的信号流通方向和方式
GPIO
LCD
有电流流过,液晶分子会以电流的方向进行排列;没有电流时,平行排列
基本原理: 通过给不同的液晶单元供电,控制其光线的通过与否而达到显示的目的
触摸屏
ADC
DAC
第十一讲 嵌入式操作系统 嵌入式操作系统 相对于通用操作系统,嵌入式操作系统更为精巧, 但并不意味着可以通过裁剪通用操作系统来实现, 它有自身的特点:
实时性
可移植性
可配置、可裁剪性
可靠性
应用编程接口
嵌入式操作系统的任务 主要任务是尽可能地屏蔽底层硬件的差异 ,对上层应用软件和底层硬件提供标准化服务
嵌入式操作系统的功能 内核是嵌入式操作系统的基础, 具有以下功能:
任务管理
中断管理
通信, 同步和互斥机制
内存管理
I/O管理
嵌入式操作系统的实时性 实时性是实时内核最重要的特征之一
实时系统的正确性不仅依赖于系统计算的逻辑结果(计算逻辑 ),还依赖于产生这些结果的时间(计算时间 )
相关概念
确定性
实时性是指内核应该尽可能快的响应外部事件
确定性是指对事件响应的最坏时间是可预知的
响应性
确定性关心系统在识别外部事件之前的延迟(响应启动延迟 )
响应性关心的是在识别外部事件后,系统要花多长时间来服务该事件(响应时间 )
响应时间
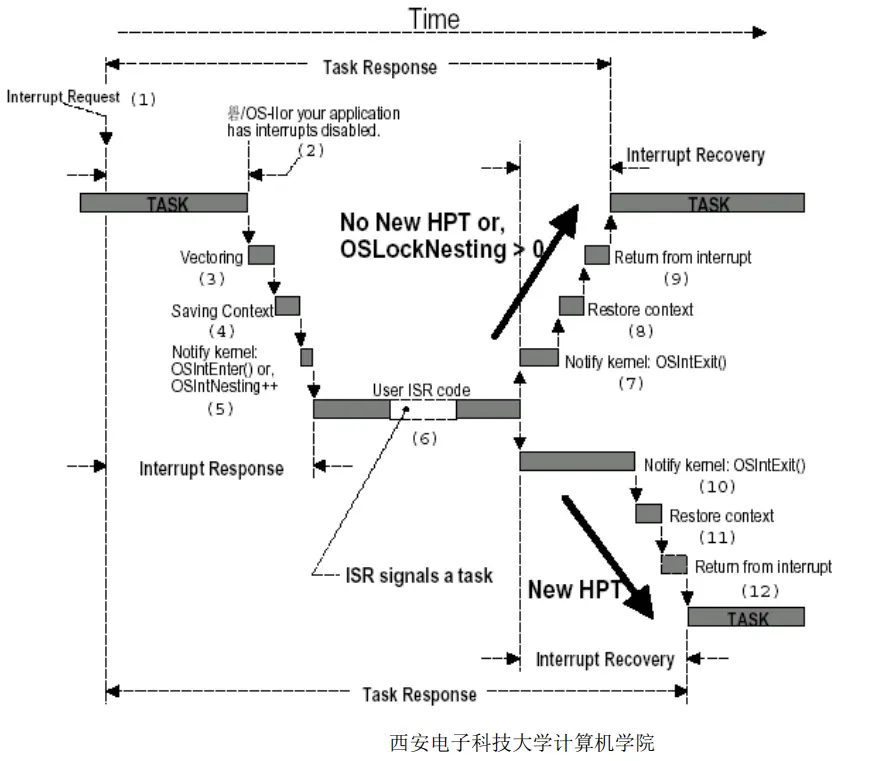
中断响应时间 = 最长关中断时间 + 保护CPU内部寄存器的时间 + 进入中断服务函数的执行时间 + 开始执行中断服务程序(ISR)的第一条指令时间
任务响应时间 = 中断响应时间+中断服务时间
对于强实时内核,响应时间应该在 $\mu s$ 级
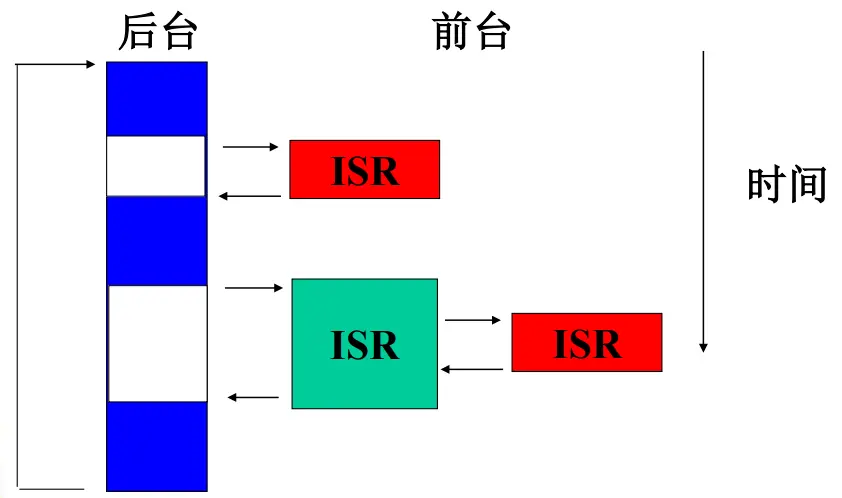
多任务程序设计结构 前后台结构
后台行为: 应用程序是一个无限的循环,循环中调用相应的函数完成相应的操作,这部分可以看成后台行为
前台行为: 中断服务程序处理异步事件,这部分可以看成前台行为
多任务系统的相关概念 嵌入式实时系统中,多采用多任务程序设计的方法,其特点有:
单个任务规模较小,容易编码和调试
任务间独立性高、耦合性小,便于扩充功能
系统实时性强,以保证紧急事件得到优先处理
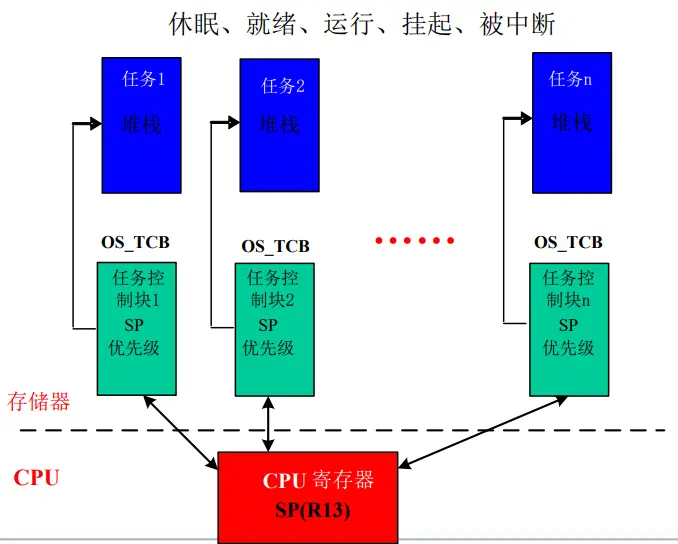
任务的概念 进程是资源分配的最小单位 , 线程是进程内部一个相对独立的控制流,是调度执行的最小单位
大多数实时内核都把整个应用当作一个没有定义的进程,应用则被划分为多个任务来处理
整个内核是一个单进程/多线程模型,简单称为多任务模型
【概念阐述】
代码: 一段可执行的程序
初始数据: 程序执行所需的相关数据
堆栈: 保存局部变量和现场的存储区
任务控制块: 包含任务相关信息的数据结构以及任务执行过程中所需要的所有信息
【任务的特点】
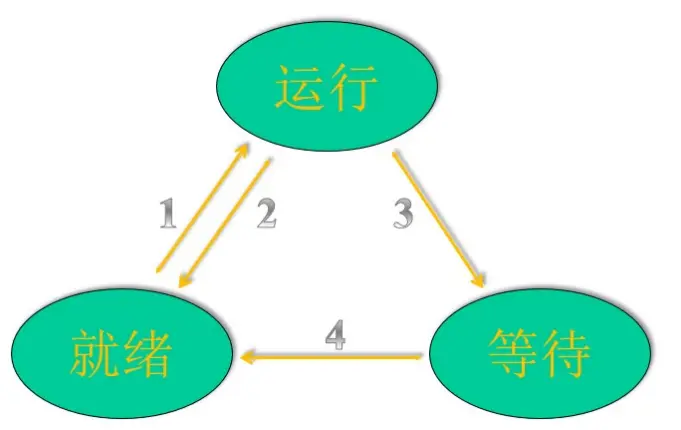
任务的基本状态及转换
运行状态(running)
阻塞状态(wait)
就绪状态(ready)
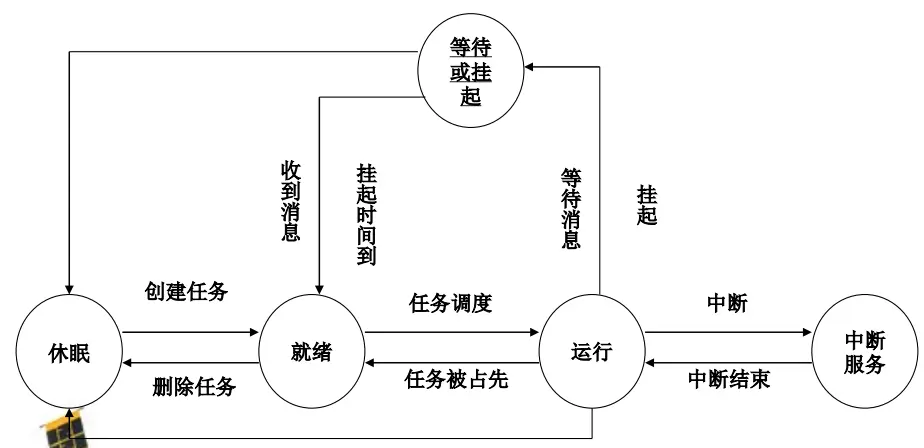
就绪$\longrightarrow$运行
运行$\longrightarrow$就绪
运行进程用完了时间片(时间片用完)
运行进程被中断,因为一高优先级进程处于就绪状态(被高优先级进程抢占)
运行$\longrightarrow$等待
OS尚未完成服务
对一资源的访问尚不能进行
初始化I/O 且必须等待结果
等待$\longrightarrow$就绪
任务的切换
保存当前任务的上下文保存正在运行任务的当前状态 ,即CPU寄存器中的全部内容 被保存到任务的当前状态保存区(任务自己的堆栈区)
恢复需要运行任务的上下文该任务的堆栈中 重新装入CPU寄存器 ,并开始下一个任务的运行
任务的调度 【调度的功能】
用来确定多任务环境下任务执行的顺序(任务执行顺序)
用来确定任务获得CPU资源后能够执行的时间(任务执行时间)[基于时间片的调度]
【调度点与调度时机】
中断服务程序的结束位置
任务因等待资源而进入等待状态
调度策略
实时任务就绪的原因
中断处理过程中 使实时任务就绪: 存在任务请求中断, 中断服务程序会使得中断请求任务就绪【中断处理程序】当前运行任务调用操作系统功能 ,使实时任务就绪【系统调用】
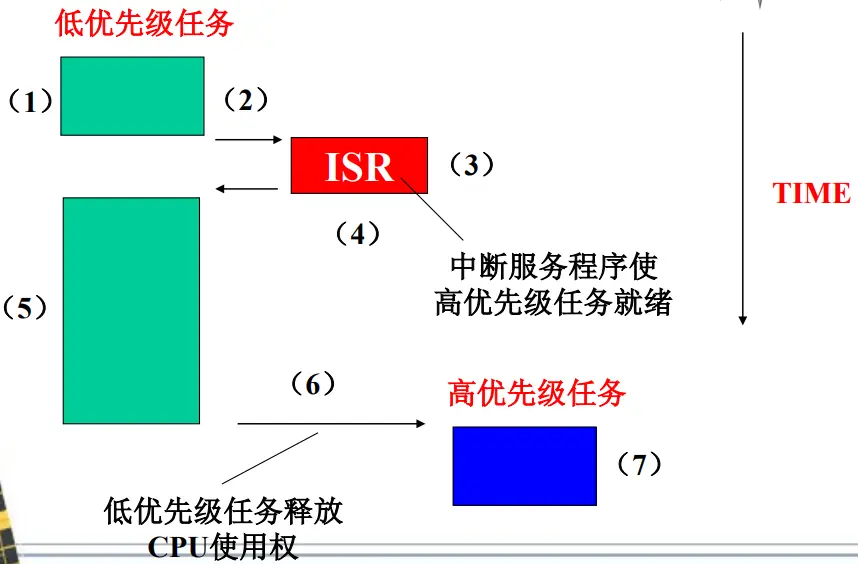
非抢占式调度
低优先级任务运行过程中,一个中断到达;
若中断被允许,CPU进入中断服务程序;
中断处理过程使一个高优先级任务就绪;
中断完成后,CPU归还给原先被中断的低优先级任务;
低优先级任务继续运行;
低优先级任务完成或因其它原因被阻塞而释放CPU,内核进行任务调度,切换到就绪的高优先级任务;【调度点】
高优先级任务运行
特点
任务运行空间是封闭的,几乎不需要使用信号量保护共享数据
内核的任务级响应时间是不确定的 ,完全取决于当前任务何时释放CPU
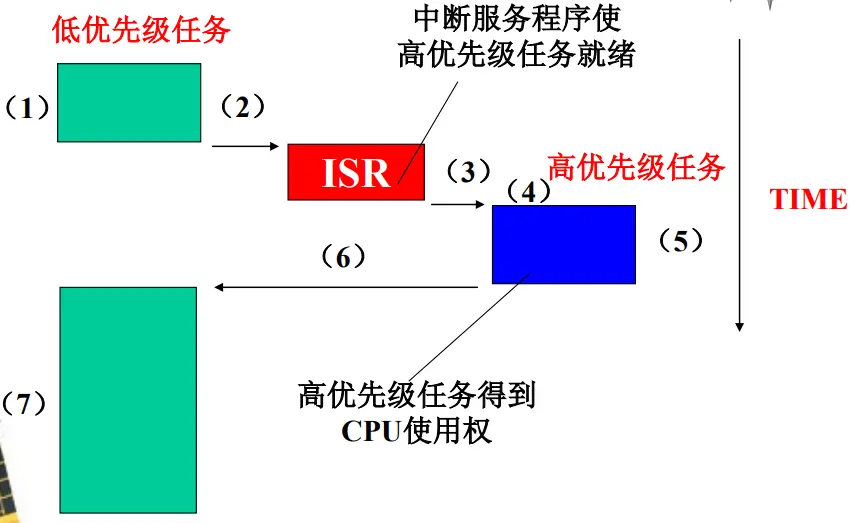
抢占式调度
低优先级任务运行过程中,一个中断到达;
若中断被允许,CPU进入中断服务程序;
中断处理过程使一个高优先级任务就绪;
中断完成后,内核进行任务调度,让刚就绪的高优先级任务获得CPU;【调度点】
高优先级任务运行;
高优先级任务完成或因其它原因被阻塞而释放CPU,内核进行任务调度;【调度点】
低优先级任务获得CPU,从被中断的代码处继续运行
特点
最高优先级的任务一旦就绪,总能得到CPU的控制权
任务运行空间不再是封闭的 ,任务不可使用不可重入型函数需要对共享数据进行必要的保护
实时操作系统大多基于抢占式内核
可重入型函数的理解
可重入型函数
该函数可以被一个以上的任务调用,而不必担心数据被破坏[基本特点]
可重入型函数任何时候都可以被中断,一段时间以后又可以运行,而相应数据不会丢失[可以随时中断或运行]
可重入型函数只使用局部变量 ,即变量保存在CPU寄存器中或堆栈中
【注解】这使得可重入型函数在发生中断时,其数据会被中断处理程序自动保存,当中断返回后,数据从堆栈中自动恢复,因此不会丢失任何数据.
不可重入型函数 1 2 3 4 5 6 7 int temp;void swap (int *x, int *y) { temp = *x; *x = *y; *y = temp; }
可重入型函数 1 2 3 4 5 6 7 void swap (int *x, int *y) { int temp; temp = *x; *x = *y; *y = temp; }
对临界区的理解 【基本概念】
在进入临界区之前要关中断
临界区代码执行完以后要立即开中断
【内核的关中断时间】
关中断影响中断延迟时间
内核在中断响应时间上的差异主要来自内核最大关中断时间
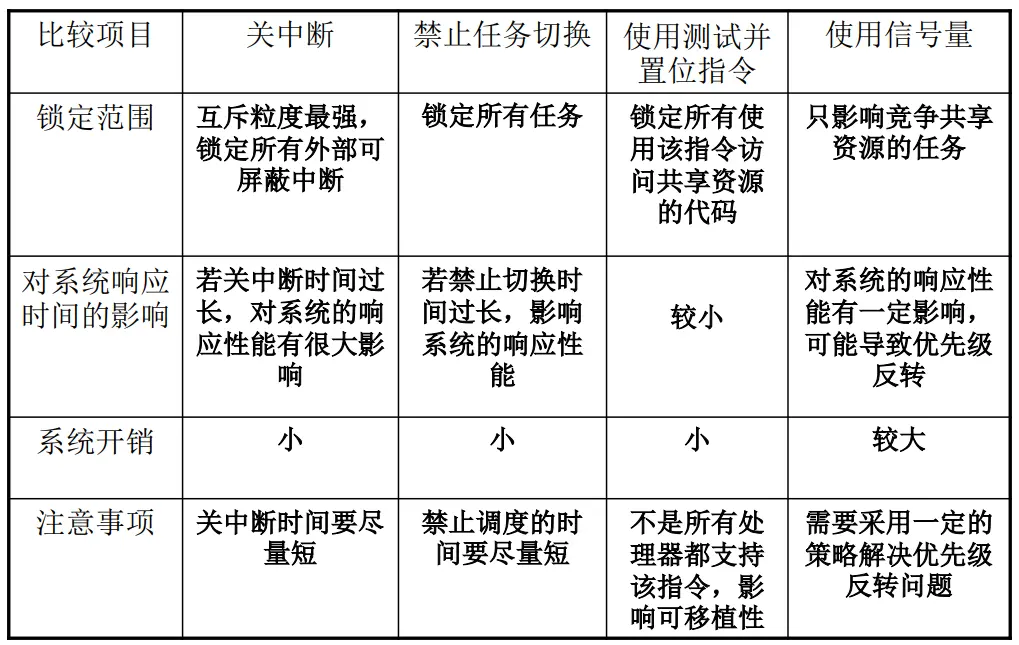
对共享资源的互斥管理
关中断
禁止任务切换
使用测试并置位指令
使用信号量(提供任务间通信、同步和互斥的最优选择
实时内核的重要性能指标 【时间性能指标】
中断延迟时间
中断延迟时间 = 最大关中断时间 + 中断嵌套的时间+ 硬件开始处理中断到开始执行ISR第一条指令之间的时间
缩短关中断时间: 在临界区的一些非关键代码段开中断,增加内核代码中的可抢占点
中断响应时间
中断响应时间 = 中断延迟时间 + 保存CPU内部寄存器的时间 + 该内核的ISR进入函数的执行时间
中断恢复时间
中断恢复时间 = 恢复CPU内部寄存器的时间 + 执行中断返回指令的时间
任务响应时间
内核调度算法是决定调度延迟的主要因素
基于优先级的抢占式调度内核中,调度延迟比较小
第十二讲 $\mu$C/OS-II的内核结构 $\mu$C/OS-II 中任务的状态 $\mu$C/OS–II支持最多64个任务,每个任务有一个特定的优先级,且优先级越高,其数值越小
运行态(运行)
就绪态(可以运行)
挂起态(不可运行)
中断服务态(不属于多任务管理的范围)
休眠态(不属于多任务管理的范围)
【任务控制块(TCB)】
任务控制块OS_TCB保存着该任务的相关参数
任务堆栈指针、状态、优先级、任务表位置、任务链表指针等
所有的任务控制块均在$\mu$C/OS-II初始化时生成,分别存在于两条链表中: 空闲链表和使用链表
任务就绪表的工作机制 空闲任务列表
初始态:所有任务控制块都被放置在任务控制块列表数组中
系统初始化: 所有任务控制块被链接成空任务控制块的单向链表
任务建立: 空任务控制块指针指向的任务控制块分配给该任务,链表中指针进行后移
任务队列 一般情况下,操作系统通过任务队列的方式进行任务管理。将任务组织为就绪队列和等待队列:
任务就绪时,把任务控制块放在就绪队列尾
任务挂起时,把任务控制块放在等待队列尾
从就绪任务队列选择当前运行任务
【特点】任务处理时间与任务数量密切相关
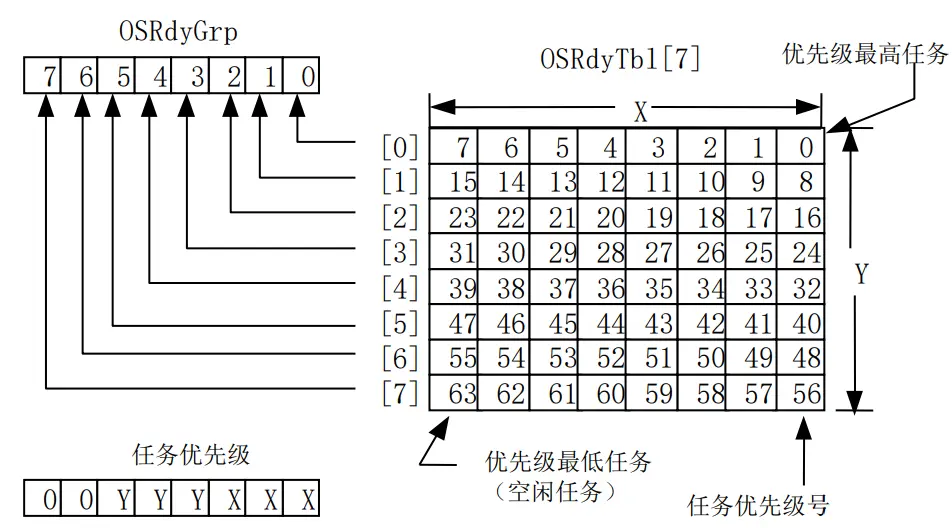
优先级位图算法 【任务就绪表】
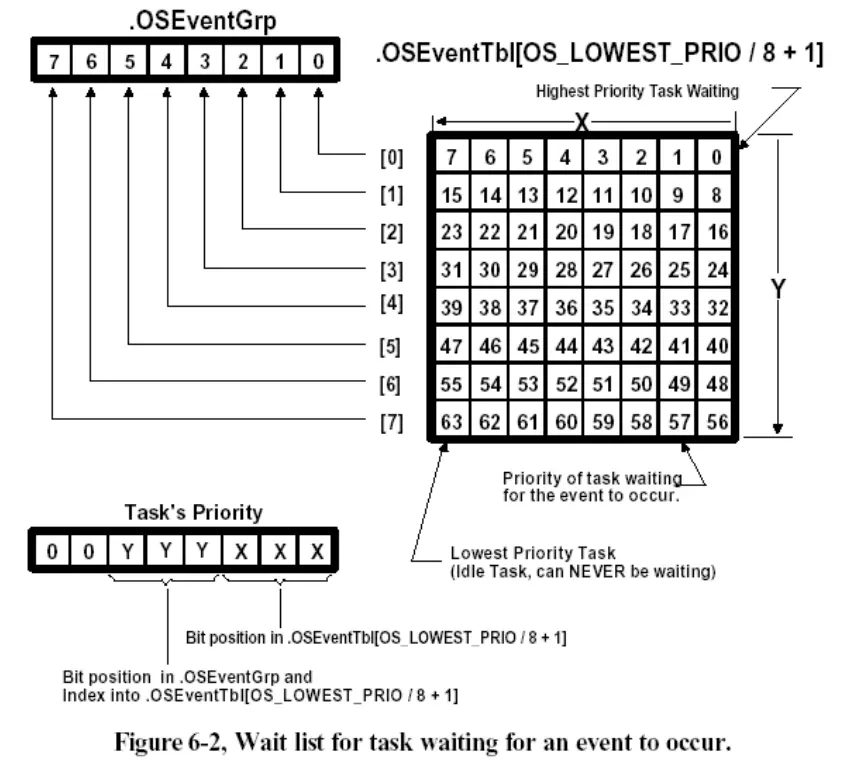
优先级位图: 任务状态分为就绪态和非就绪态,对应两个状态,一比特位编码
任务优先级(0$\sim 63$)划分为组号(高三位)与组内编号(低三位),并且高优先级对应小的优先级号,其中组号索引OSRdyTbl,用组内编号索引OSRdyTbl
OSRdyTbl类似二维数组,每个元素对应就绪表每一行
OSRdyGrp数组标记OSRdyTbl的每一行是否存在1,即全组任务中没有一个进入就绪态时,OSRdyGrp的相应位才为零
掩码数组OSMapTbl[7]用于对OSRdyTbl和OSRdyGrp置位,预存数组,使用时只是一次取内存的操作
OSMapTbl[0]=$2^0$=0x01(0000 0001)
OSMapTbl[1]=$2^1$=0x02(0000 0010)
OSMapTbl[7]=$2^7$=0x80(1000 0000)
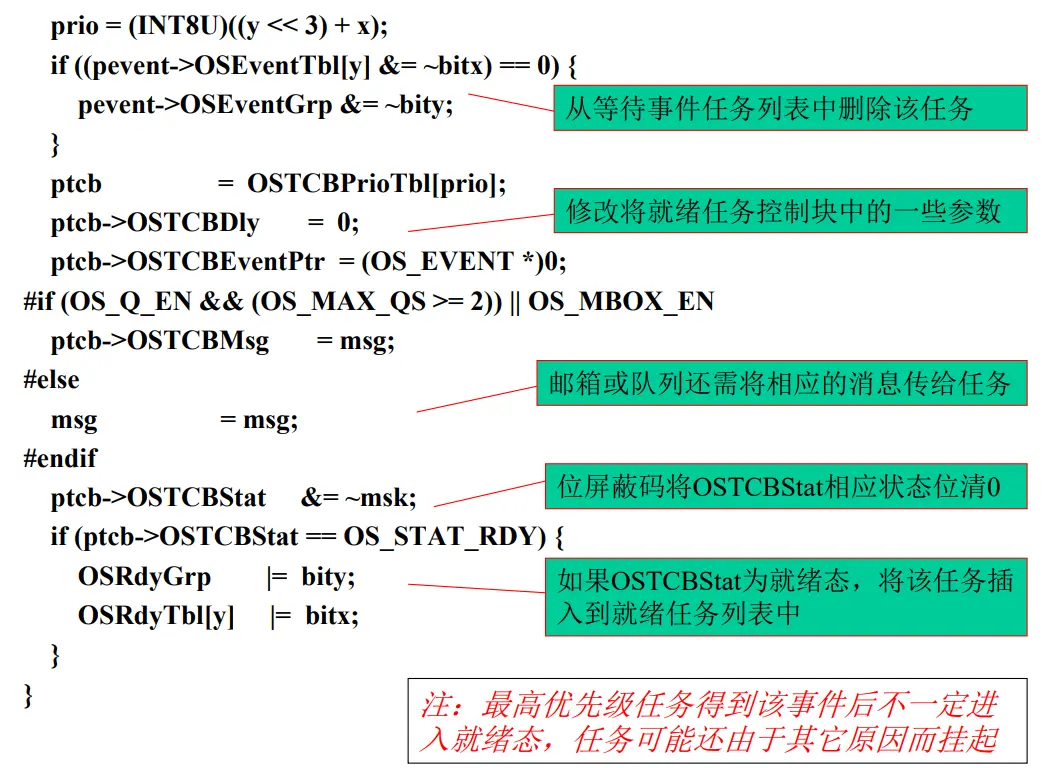
Op1: 使任务进入就绪态
OSRdyGrp |= OSMapTbl[prio>>3]
OSRdyTbl[prio>>3] |= OSMapTbl[prio & 0x07]
Op2: 使任务脱离就绪态
If((OSRdyTbl[prio>>3] &= ∼OSMapTbl[prio & 0x07])== 0)
OSRdyGrp &= ∼OSMapTbl[prio>>3]
Op3: 根据就绪表确定最高优先级
$\max prio = j*8+i$
查表法具有确定的时间,增加了系统的可预测性,$\mu$C/OS中所有的系统调用时间都是确定的
High3 = OSUnMapTbl[OSRdyGrp]
Low3 =OSUnMapTbl[OSRdyTbl[High3]]
Prio =(Hign3<<3)+Low3
【注解】
$\mu$C/OS 的任务级和中断级调度
$\mu$C/OS-II总是选择运行进入就绪态任务中优先级最高的任务;
以优先级为下标 ,即可得相应任务控制块$\mu$C/OS-II任务调度的执行时间为常数,与当前建立的任务数没有关系
任务级调度 任务级调度 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 void OSSched (void ) { INT8U y; OS_ENTER_CRITICAL(); if ((OSLockNesting | OSIntNesting) == 0 ){ y = OSUnMapTbl[OSRdyGrp]; OSPrioHighRdy != (INT8U)(y<<3 + OSUnMapTbl[OSRdyTbl[y]]); if (OSPrioHighRdy != OSPrioCur){ OSTCBHighRdy = OSTCBPrioTbl[OSPrioHighRdy]; OSCtxSwCtr++; OS_TASK_SW(); } } OS_EXIT_CRITICAL(); }
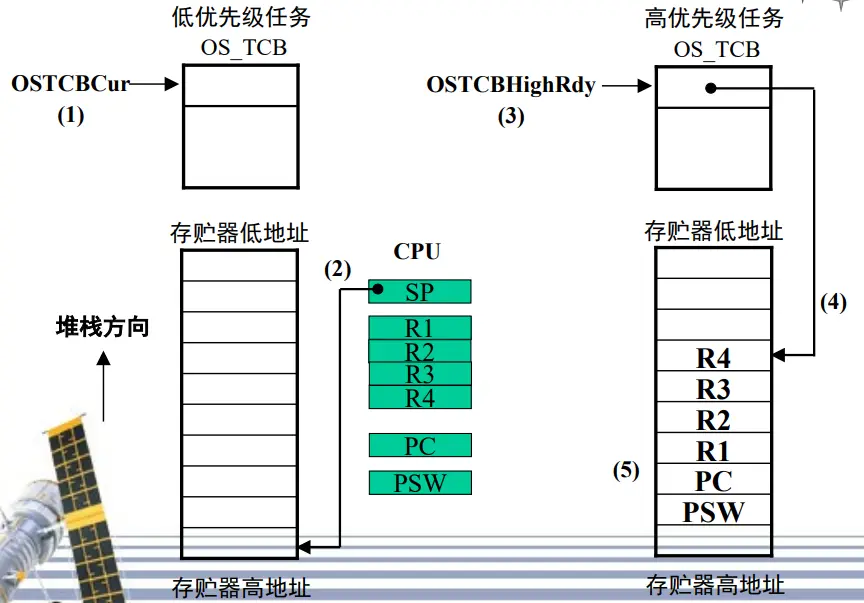
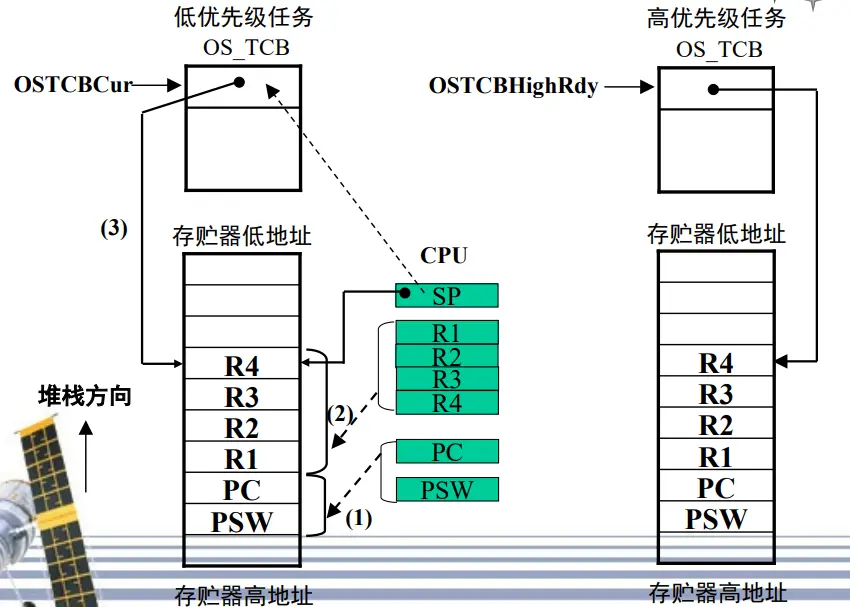
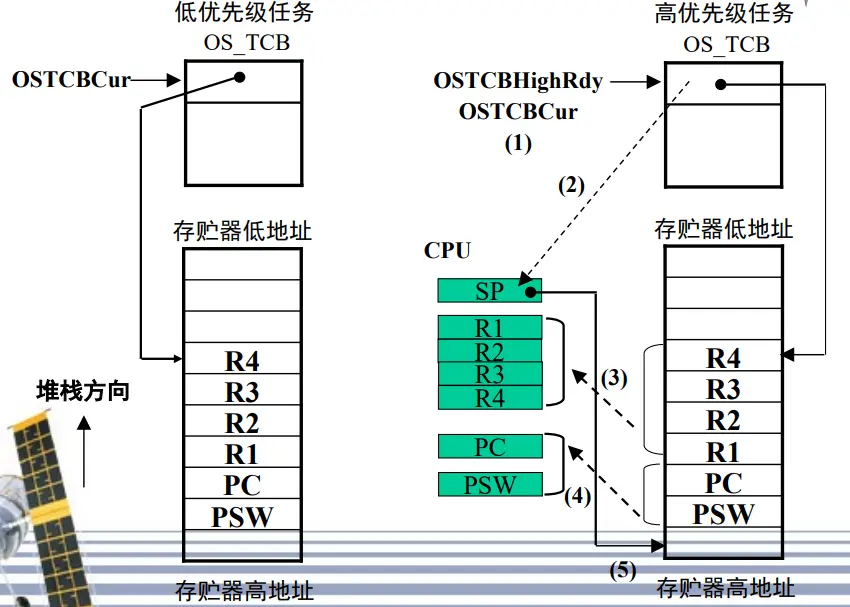
【任务切换】
将被挂起的任务寄存器入栈
将较高优先级任务的寄存器值出栈,回复到CPU寄存器中
调度器上锁机制 注解:如果需要保护一个任务不被切换,可以使用关中断,但是力度太大导致不能响应中断;$\mu$cos采用调度器上锁机制,实现了保护任务同时可以响应中断的目的.
OSSchedlock()
该函数用于禁止任务调度直到调用给调度器开锁函数为止
中断可以识别,中断服务也能得到
OSLockNesting跟踪该函数被调用的次数
OSSchedUnlock()
OSSchedLockFunction 1 2 3 4 5 6 7 8 void OSSchedLock (void ) { if (OSRunning == TRUE){ OS_ENTER_CRITICAL(); OSLockNesting++; OS_EXIT_CRITICAL(); } }
OSLockNesting是一个全局变量,因此在进行访问时需要关中断;同时OSLockNesting记录加锁的个数
OSSchedUnlockFunction 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 void OSSchedUnlock (void ) { if (OSRunning == TRUE){ OS_ENTER_CRITICAL(); if (OSLockNesting > 0 ){ OSLockNesting--; if ((OSLockNesting | OSIntNesting) == 0 ){ OS_EXIT_CRITICAL(); OSSched(); }else { OS_EXIT_CRITICAL(); } }else { OS_EXIT_CRITICAL(); } } }
当OSLockNesting减到0(没有处于中断)时, 再次进行一次任务调度,调度之前可能需要被调度的任务
中断级调度 基于抢占式的中断调度,在中断返回的时候进行任务的调度,检测是否有更高优先级的任务已经就绪。
中断结束时调用返回函数OSIntExit(), OSIntExit()将中断嵌套计数器OSIntNesting减1;
当计数器减到0时,对就绪任务做判断,并返回到任务:
有更高优先级任务就绪,返回更高优先级任务
否则,返回到被中断任务
OSIntEnterFunction 1 2 3 4 5 6 void OSIntEnter (void ) { OS_ENTER_CRITICAL(); OSIntNesting++; OS_EXIT_CRITICAL(); }
OSIntExitFuntion 1 2 3 4 5 6 7 8 9 10 11 12 13 14 void OSIntExit (void ) { OS_ENTER_CRITICAL(); if ((--OSIntNesting | OSLockNesting) == 0 ){ OSIntExitY = OSUnMapTbl[OSRdyGrp]; OSPrioHighRdy = (INT8U)((OSIntExitY << 3 ) + OSUnMapTbl[OSRdyTbl[OSIntExitY]]); if (OSPrioHighRdy != OSPrioCur){ OSTCBHighRdy = OSTCBPrioTbl[OSPrioHighRdy]; OSCtxSwCtr++; OSIntCtxSw(); } } OS_EXIT_CRITICAL(); }
OSIntNesting的数值标识中断嵌套的层数,是一个全局变量;
中断返回时判断是否为0,当为0时意味着中断已全部返回并且调度器没有上锁时,进行一次任务调度;
如果最高优先级任务不是当前任务,则进行任务切换,否则不切换;
区别:
任务级调度每次都需要保护现场,并恢复现场;
而中断级的调度,在进行中断时以保存过现场,因此在调度时只需恢复现场;
因此任务级调度的任务切换函数OS_TASK_SW()与中断级调度的任务切换函数OSIntCtxSw()不同;
OSIntNesting 与 OSLockNesting 两种嵌套方式相互独立,互不影响,保证了任务不切换但是可以响应中断
时钟节拍
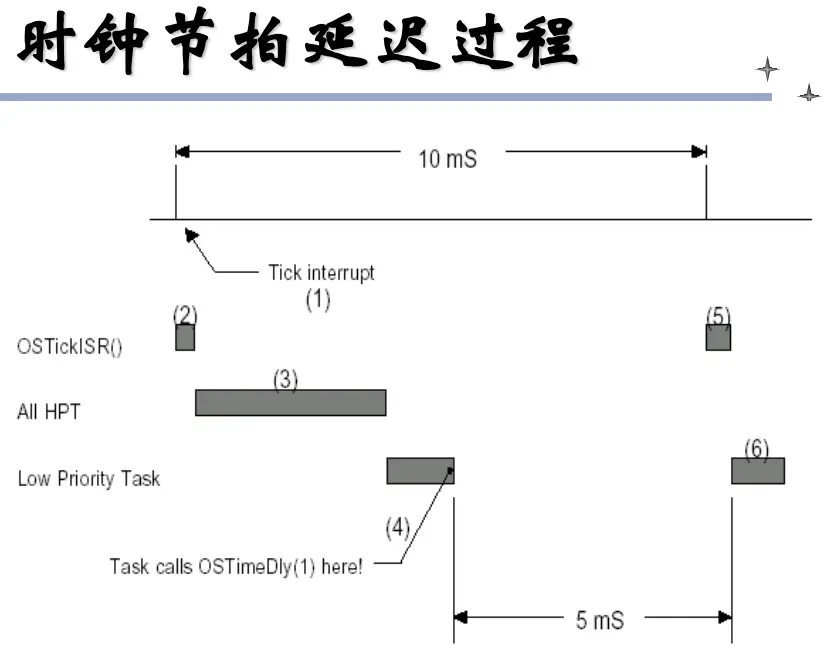
时钟节拍(时钟滴答)Tick,是一种定时器中断 ,可通过编程方式实现
时钟节拍是一种特殊的中断 ,是操作系统的心脏
中断服务子程序中,首先对32位的整数OSTime加一(OSTime记录系统启动以来的时钟滴答数)
对任务列表进行扫描,判断是否有延时任务已经处于就绪状态,最后进行上下文切换
OSTickISRFunction 1 2 3 4 5 6 7 8 9 10 11 12 13 14 void OSTickISR (void ) { 保存处理器寄存器的值; 调用OSIntEnter()或是将OSIntNesting+1 if (OSIntNesting == 1 ){ OSTCBCur -> OSTCBStkPtr = SP; } 调用OSTimeTick(); 清发出中断设备的中断; 重新允许中断(可选用); 调用OSIntExit(); 恢复处理器寄存器的值; 执行中断返回指令; }
OSTimeTickFunction 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 void OSTimeTick (void ) { OS_TCB *ptcb; ptcb = OSTCBList; while (ptcb->OSTCBPrio != OS_IDLE_PRIO){ if (ptcb -> OSTCBDly != 0 ){ if (--ptcb->OSTCBDly == 0 ){ if (!(ptcb->OSTCBStat & OS_STAT_SUSPEND)){ OSRdyGrp |= ptcb->OSTCBBitY; OSRdyTbl[ptcb->OSTCBY] |= ptcb->OSTCBBitX; }else { ptcb->OSTCBDly = 1 ;} } } ptcb = ptcb -> OSTCBNext; } OSTime++; }
【注解】时钟中断做为一种特殊的中断,需要保存上下文环境,然后进入到真正的用户中断服务程序,最后中断返回,回复上下文环境
第十三讲 $\mu$COS-II的任务管理
任务管理用来实现对任务状态的直接控制和访问
内核的任务管理是通过系统调用(等待、延时等)来体现的[不然会阻塞CPU, 保证能够分时进行]
任务的创建 【任务创建时机】
多任务调度OSStart()开始前[初始化创建任务]
其他任务执行过程中[任务执行时又创建或删除任务]
任务不能由中断服务程序建立[中断服务程序不属于多任务管理的范畴,不能参与任何的任务管理工作:不能在中断中创建任务和删除任务,检测OSIntNesting是否为0,大于0表示有中断或中断嵌套]
【参数作用】
task: 指向任务代码的指针
pdata: 任务开始时,传递给任务的指针参数
ptos: 分配给任务的堆栈栈顶指针
prio: 分配给任务的优先级
【任务创建代码分析】
OSTaskCreateFunction 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 INT8U OSTaskCreate (void (*task)(void *pd), void *pdata, OS_STK *ptos, INT8U prio) { void *psp; INT8U err; if (prio > OS_LOWEST_PRIO){ return (OS_PRIO_INVALID); } OS_ENTER_CRITICAL(); if (OSTCBPrioTbl[prio] == (OS_TCB *)0 ){ OSTCBPrioTbl[prio] = (OS_TCB *)1 ; OS_EXIT_CRITICAL(); psp = (void *)OSTaskStkInit(task, pdata, ptos, 0 ); err = OSTCBInit(prio, psp, (void *)0 , 0 , 0 , (void *)0 , 0 ); if (err == OS_NO_ERR){ OS_ENTER_CRITICAL(); OSTaskCtr++; OS_EXIT_CRITICAL(); if (OSRuning){ OSSched(); } }else { OS_ENTER_CRITICAL(); OSTCBPrioTbl[prio] = (OS_TCB *)0 ; OS_EXIT_CRITICAL(); } return (err); }else { OS_EXIT_CRITICAL(); return (OS_PRIO_EXIST); } }
【注解】首先进行优先级占位而非直接申请任务控制块,主要是因为提前判断是否有其他任务占用此优先级,速度比初始化任务控制块更快。
MainFunction 1 2 3 4 5 6 7 void main () { OSInit(); OSTaskCreate(Task1, (void *)&Task1Data, (void *)&Task1Stk[TASK_STK_SIZE], Task1prio); OSTaskCreate(Task2, (void *)&Task2Data, (void *)&Task2Stk[TASK_STK_SIZE], Task2prio); OSStart(); }
OSStartFunction 1 2 3 4 5 6 7 8 9 10 11 12 13 void OSStart (void ) { INT8U y, x; if (OSRunning == FALSE){ y = OSUnMapTbl[OSRdyGrp]; x = OSUnMapTbl[OSRdyTbl[y]]; OSPrioHighRdy = (INT8U)((y<<3 )+x); OSPrioCur = OSPrioHighRdy; OSTCBHighRdy = OSTCBPrioTbl[OSPrioHighRdy]; OSTCBCur = OSTCBHighRdy; OSStartHighRdy(); } }
【任务堆栈】
堆栈的分配
静态分配——保证位于程序的RW段
static OS_STK MyTaskStack[stack_size] 局部静态变量OS_STK MyTaskStack[stack_size] 全局变量
动态分配——位于程序的堆中,但一直不释放1 2 3 4 5 OS_STK *pstk; pstk = (OS_STK*)malloc (stack_size); if (pstk!=(OS_STK*)0 ){ create the task; }
【注解】malloc在程序堆(不同于堆栈)中分配内存,有可能会产生内存碎片,导致分配失败; 并且分配的堆栈绝对不能位于程序的栈中。
【任务删除】
使任务返回,并处于休眠状态
任务代码并不被删除,只是不再被调用
OSTaskDelFunction 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 INT8U OSTaskDel (INT8U prio) { OS_TCB *ptcb; OS_EVENT *pevent; if (prio == OS_IDLE_PRIO){ return (OS_TASK_DEL_IDLE); } if (prio >= OS_LOWEST_PRIO && prio != OS_PRIO_SELF){ return (OS_PRIO_INVALID); } OS_ENTER_CRITICAL(); if (OSIntNesting > 0 ){ OS_EXIT_CRITICAL(); return (OS_TASK_DEL_ISR); } if (prio == OS_PRIO_SELF){ prio = OSTCBCur->OSTCBPrio; } if ((ptcb = OSTCBPrioTbl[prio]) != (OS_TCB *)0 ){ if ((OSRdyTbl[ptcb->OSTCBY] &= ~ptcb->OSTCBBitX) == 0 ){ OSRdyGrp &= ~ptcb->OSTCBBitY; } if ((pevent = ptcb->OSTCBEventPtr) != (OS_EVENT *)0 ){ if ((pevent->OSEventTbl[ptcb->OSTCBY] &= ~ptcb->OSTCBBitX) == 0 ){ pevent->OSEventGrp &= ~ptcb->OSTCBBitY; } } ptcb->OSTCBDly = 0 ; ptcb->OSTCBStat = OS_STAT_RDY; OSLockNesting++; OS_EXIT_CRITICAL(); OSDummy(); OS_ENTER_CRITICAL(); OSLockNesting--; OSTaskDelHook(ptcb); OSTaskCtr--; OSTCBPrioTbl[prio] = (OS_TCB*)0 ; if (ptcb->OSTCBPrev == (OS_TCB *)0 ){ ptcb->OSTCBNext->OSTCBPrev = (OS_TCB*)0 ; OSTCBList = ptcb->OSTCBNext; }else { ptcb->OSTCBPre->OSTCBNext = ptcb->OSTCBNext; ptcb->OSTCBBext->OSTCBPrev = ptcb->OSTCBPrev; } ptcb->OSTCBNext = OSTCBFreeList; OSTCBFreeList = ptcb; OS_EXIT_CRITICAL(); OSSched(); return (OS_NO_ERR); }else { OS_EXIT_CRITICAL(); return (OS_TASK_DEL_ERR); } }
【注解】注重Dummy()函数的使用,以及调度器上锁,开关中断的处理,其目的是将任务删除分为两个阶段,两个阶段的间隔能够响应中断但是不能切换任务。
任务的挂起与恢复机制
任务可以挂起自己或其他任务
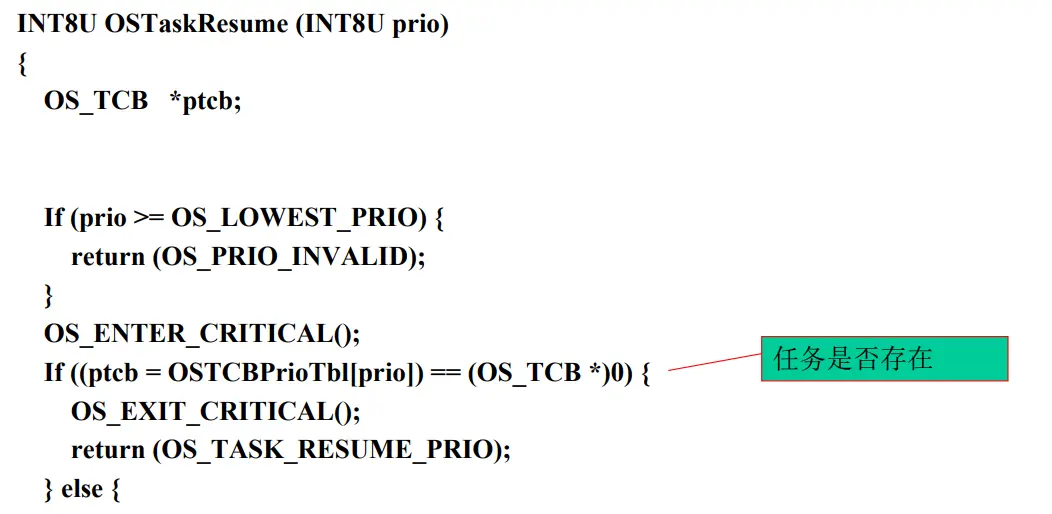
被OSTaskSuspend()函数挂起的任务只能通过调用OSTaskResume()函数来恢复
OSTaskSuspendFunction 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 INT8U OSTaskSuspend (INT8U prio) { BOOLEAN self; OS_TCB *ptcb; if (prio == OS_IDLE_PRIO){ return (OS_TASK_SUSPEND_IDLE); } if (prio >= OS_LOWEST_PRIO && prio != OS_PRIO_SELF){ return (OS_PRIO_INVALID); } OS_ENTER_CRITICAL(); if (prio == OS_PRIO_SELF){ prio = OSTCBCur->OSTCBPrio; self = TRUE; }else if (prio == OSTCBCur->OSTCBPrio){ self = TRUE; }else { self = FALSE; } if ((ptcb = OSTCBPrioTbl[prio]) == (OS_TCB*)0 ){ OS_EXIT_CRITICAL(); return (OS_TASK_SUSPEND_PRIO); }else { if ((OSRdyTbl[ptcb->OSTCBY] &= ~ptcb->OSTCBBitX) == 0 ){ OSRdyGrp &= ~ptcb->OSTCBBitY; } ptcb->OSTCBStat |= OS_STAT_SUSPEND; OS_EXIT_CRITICAL(); if (self == TRUE){ OSSched(); } return (OS_NO_ERR); } }
【任务的状态】——只能清除对应的位,不能清除其他位
任务延迟 OSTimeDly 的实现机制
【改变任务状态的两套机制】
时钟节拍的精度:10ms一次触发时钟中断,10ms做为操作系统的精度;但是精度不能无限制地提高;
【OSTimeDlyResume】
被延时的任务可以不等待延时期满,而通过OSTimeDlyResume()函数来恢复
第十四讲 $\mu$COS-II的任务通信机制 任务通信的基本知识 【信号量】[关键确定同步和互斥关系]
信号量大于等于零的时候代表可供并发进
信号量小于零的时候,表示正在等待使用
P 操作和 V 操作是不可中断的程序段,称为原语(具有原子性)
$\mu$COS-II 中事件的概念
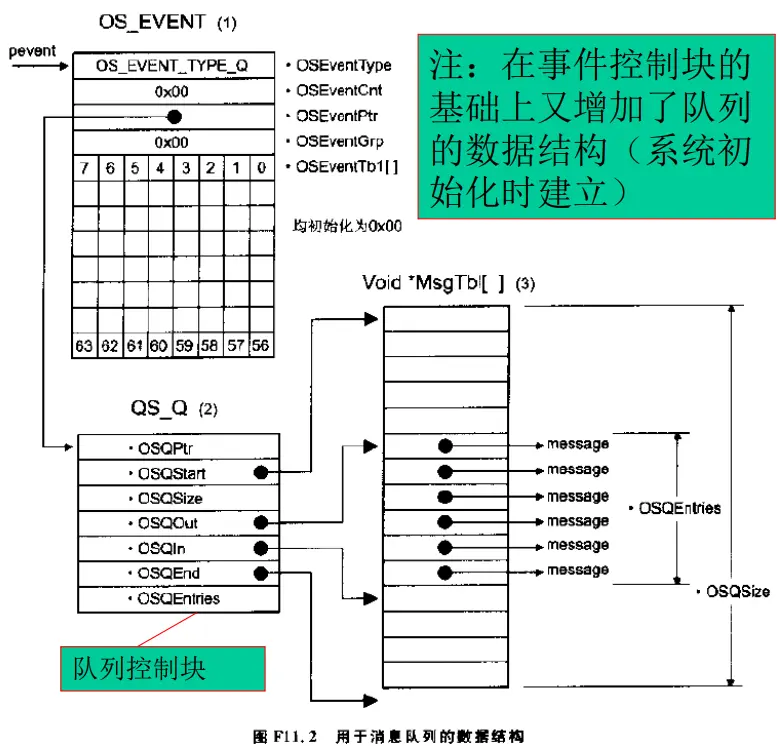
$\mu$C/OS-II中的任务间通信: 通过信号量、消息邮箱和消息队列来实现任务间通信的
【事件】
事件控制块是$\mu$C/OS-II任务管理的实现机制,统一了信号量,邮箱和队列三种方式
【等待任务列表实现机制】
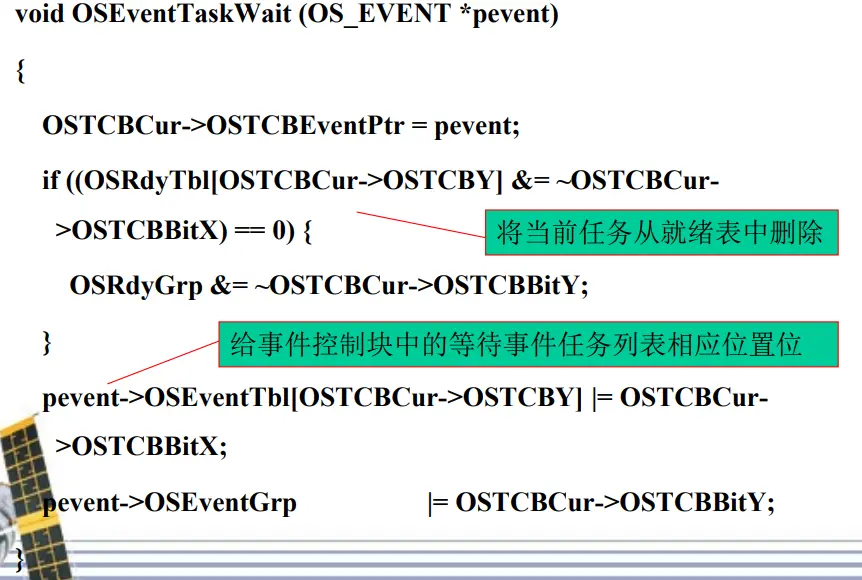
【对等待事件任务列表的三种操作】
将任务置于等待事件任务列表(加入等待事件)pevent->OSEventGrp |= OSMapTbl[prio >> 3]
pevent->OSEventTbl[prio >> 3] |= OSMapTbl[prio & 0x07]
注解:取出prio的低三位利用掩码数组OSMapTbl对组内编号置位,pevent是当前的任务控制块
单个事件控制块: 创建单个事件,对应有对多个任务在等待该事件发生,即等待事件任务列表
【对事件控制块的操作】
OSTCBStat任务状态可以等待多个事件,等信号量,邮箱,队列等,这几种机制互不影响
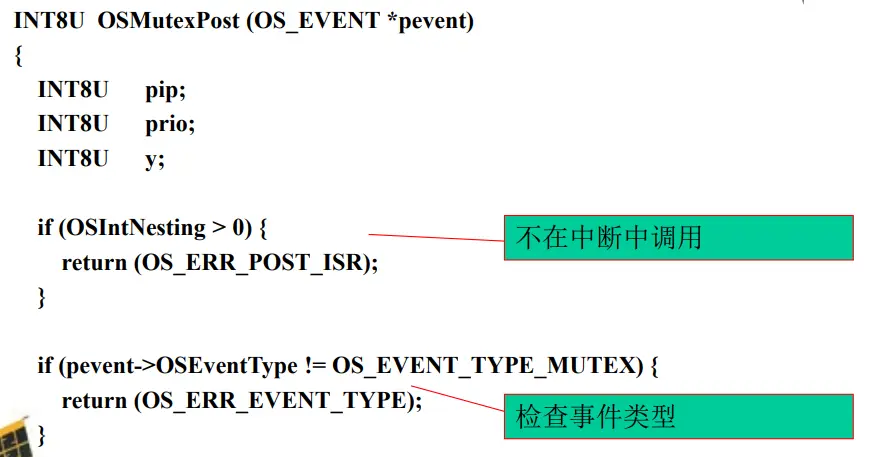
$\mu$C/OS-II 中信号量的实现机制 【创建信号量】
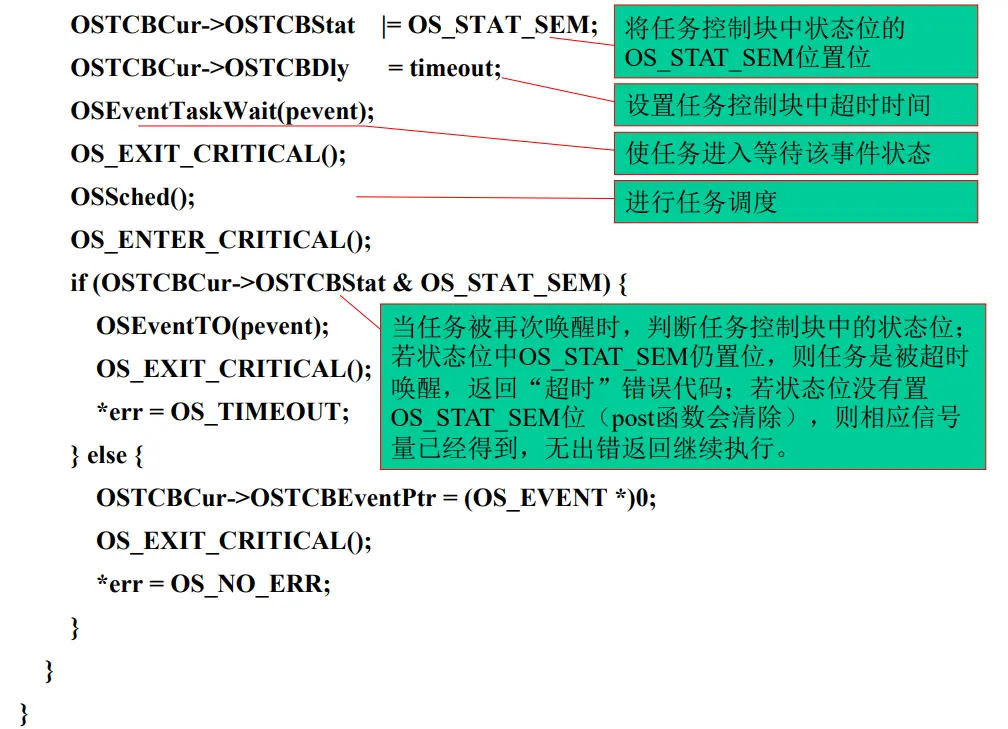
【P操作, 等待一个信号量】
【V操作, 发出一个信号量】
信号量超时机制 第十五讲 $\mu$COS-II的任务通信机制II 优先级反转的概念
背景: $\mu$C/OS-II不允许多任务处于同一优先级,在利用信号量实现互斥操作时,任务是不对等的,存在优先级差异
【优先级翻转】
【解决方案】
优先级继承协议
优先级天花板
区别
优先级继承:只有当占有资源的低优先级任务被阻塞 时,才会提高占有资源任务的优先级
优先级天花板:不论是否发生阻塞都提升
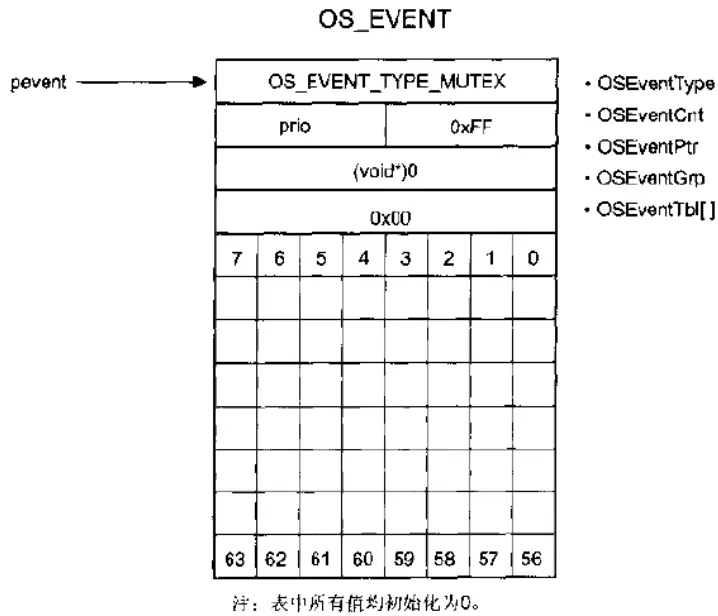
$\mu$COS-II 中互斥型信号量实现机制 【优先级继承优先级】没有被占用的 、略高于最高优先级的优先级 被保留给“优先级继承优先级(PIP)”,融合了“优先级继承”和“优先级天花板”的解决方案
【uC/OS 中互斥型信号量Mutex】——对比信号量事件的实现机制
OSEventCnt被划分为高8位和低8位,其中高8位表示保留优先级;低8位为全1时表示信号量有效没有被占用,当信号量被占用时,低8位标识占有该信号量的任务优先级即0$\sim$63
其它任务间通信机制
消息邮箱
消息队列
根据具体应用,每个指针指向的数据结构可以有所不同
可看做多个邮箱组成的数组,只是共用了同一个等待任务列表
事件标志组
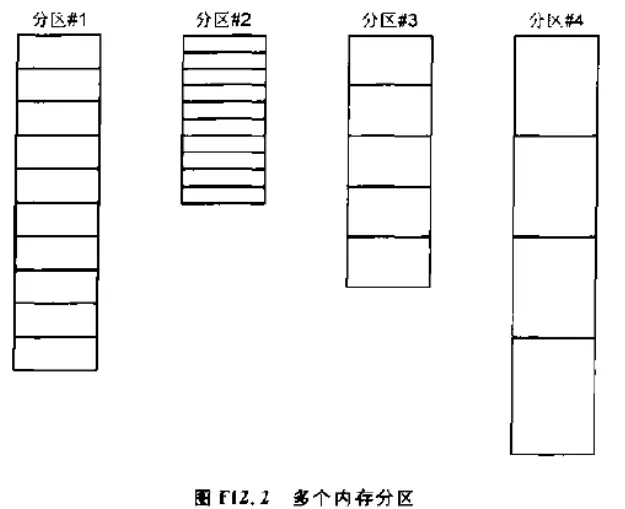
$\mu$C/OS-II的内存分区管理 $\mu$C/OS-II将内存按分区来处理
可以分配和释放固定大小的内存块
解决了内存碎片问题
分配、释放函数执行时间确定了
题型分析 简答题 嵌入式系统的定义
标准定义:以应用为中心、以计算机技术为基础,软、硬件可裁剪,适应应用系统对功能、可靠性、成本、体积、功耗等严格要求的专用计算机系统
简单描述:嵌入到对象体中的专用计算机系统
嵌入式系统的三要素
嵌入式:嵌入到对象体系中,有对象环境要求
专用性:软、硬件按对象要求裁剪
计算机:实现对象的智能化功能
嵌入式系统与通用计算机的区别
专用性
小型化(资源受限)
软硬件设计一体化
需要交叉开发环境
简述嵌入式实时系统的特点
实时性
结果正确性
可预测性
稳定性和可靠性
CPU寄存器与内存的区别
CPU寄存器是位于CPU内部的小型、高速存储单元,用于临时存储和快速访问指令和数据;
内存是位于计算机主板上的存储设备,用于存储程序和数据,供CPU读取和写入;
寄存器速度更快但容量有限,用于临时存储;
内存速度较慢但容量较大,用于长期存储。
RISC指令集只包含有少量常用指令,为什么有时反而比CISC指令集的性能更好?
指令集分析:指令复杂度影响处理器实现性能,CISC中20%的指令使用率达到80%,但80%的复杂指令使用率仅20%,而RISC只包含有少量常用指令,不会造成指令集的冗余;
指令译码逻辑:CISC指令集采用微指令技术增加了硬件复杂度,而RISC采用硬连线的指令译码逻辑,开发简单;
指令执行分析:CISC指令长度不一,执行单条指令需要多个周期,而RISC指令长度固定,一个周期执行一条指令,通过少量常用指令的组合实现复杂的功能,容易实现高性能;
Load/Store结构:RISC还采用Load/Store结构进行优化,完成数据在寄存器和存储器之间的传输,保证处理器直接从寄存器中获取操作数,能够加快运算的执行效率,实现更高的性能。
简述宏和函数的区别?二者各自的优缺点是什么?
编译阶段:编译器会将相关代码放到宏名出现的每一个地方并且宏内容会被直接展开到代码中,宏的代码在任何出现宏名的地方都会编译一次;而函数的代码只需要编译一次,在编译时定义,但是实际在执行发生在运行时
调用返回:使用宏时不需要保存/恢复上下文,也不必返回;而调用函数时,需要保存/回复上下文,需要返回,会有函数调用开销;
优缺点:宏适用于代码简单的情况,不会有函数调用开销,但是容易造成代码膨胀;函数适用于代码复杂的情况,可以完成更复杂的功能,但是会有函数调用开销。
简述ARM异常响应过程以及异常向量表的作用 【ARM异常处理】
当中断发生时,系统执行完当前指令后,会跳转到相应的异常中断处理程序处执行;
执行完成后,程序返回到发生中断的指令的下一条指 令处执行;
进入异常中断处理程序时要保存现场,返回时要恢复现场;
【异常向量表】
当异常发生时,处理器会把PC设置为一个特定的存储器地址;
这一地址放在被称为向量表(vector table)的特定地址范围内,用于对不同模式的异常提供异常处理程序的入口;
异常向量表通常放在存储地址的低端;
简述$\mu$cos中优先级位图算法的优点
常数时间选择任务,无论任务的数量如何,选择最高优先级任务的时间是确定的
实现简单,容易维护
可以快速选择最高优先级任务
内存占用低
在ARM汇编语言程序里,什么是伪指令,他们有什么作用?
ARM伪指令不是真正的ARM指令,在汇编编译器对源程序进行汇编处理时会被替换成对应的ARM指令或指令序列
伪指令主要用于指导汇编器怎样对源程序进行汇编,在汇编后不会生成机器码,仅在汇编过程中起作用
能否用全局变量来实现任务间的通信?它有什么优缺点?该如何正确使用? 可以用全局变量实现任务间的通信
优点:
简单直观: 使用全局变量简化了任务间通信的实现,因为所有任务都能够直接访问这些共享变量
高效: 全局变量的访问通常比通过消息传递等其他通信机制更为高效,因为直接在内存中进行读写操作
缺点:
缺少同步与互斥关系的管理机制: 如果多个任务同时尝试读取或写入全局变量,可能导致意外行为和数据损坏
难以调试: 由于多个任务可以同时访问全局变量,发现和调试由于共享变量而引起的问题可能会更加困难
扩展性差: 当系统规模扩大时,全局变量的管理和维护可能变得复杂,使得系统的扩展性变差
正确使用的方法:
加锁机制: 在访问全局变量时,使用加锁机制确保同一时间只有一个任务可以访问该变量,从而避免相互竞争
原子操作: 对于某些特定的变量操作,可以使用原子操作,保证执行单条指令不会被中断,例如SWP实现互斥访问
信号量机制: 使用信号量机制来确保对全局变量的安全访问
$\mu$cos中任务的调度一般分为任务级调度和中断级调度,简述二者的区别
调度触发条件:任务级调度是当前任务放弃CPU触发的,中断级调度是由中断事件触发的
调度时机不同:任务级调度是在时间片用完、被高优先级任务抢占或等待某个事件时进行的,而中断级调度在中断返回的时候进行任务的调度
恢复现场不同:任务级调度在调度点每次都需要保护现场并恢复现场,而中断级调度因为在进行中断处理时已保存过现场,因此在调度点只需恢复现场
任务级调度与中断级调度是两套独立的机制,互不影响
优先级反转如何发生?又如何解决? 优先级反转现象:
优先级继承协议
优先级天花板
优先级继承优先级
简述$\mu$cos中解决互斥的3种办法,以及它们各自的优缺点
关中断
优点:简单直接,实现较为容易
缺点:力度较大,一旦使用会阻塞整个系统;不适用于实时系统,可能导致系统响应不及时
禁止任务切换——调度器上锁机制
优点:系统开销较小,
缺点:由于锁定所有任务,所以若禁止切换时间过长,影响系统的响应性能
使用信号量
优点:只影响竞争共享资源的任务
缺点:虽然$\mu$cos提出了互斥型信号量机制来解决优先级反转问题,但是这种方法的系统开销较大,对系统的响应性能会有一定影响
冯诺依曼体系结构与哈佛体系结构的区别?
存储器结构:冯诺依曼体系结构中程序指令存储器和数据存储器共用同一个存储体,而哈佛体系结构使用两个独立的存储器模块,分别存储指令和数据;
位宽:冯诺依曼体系结构中程序指令和数据宽度相同,而哈佛体系结构可以不同;
总线:冯诺依曼体系结构使用一条总线传输,而哈佛体系结构采用两条独立的总线,互不影响。
理解Load/Store结构
在通用寄存器中操作,从存储器中读某个值到寄存器,操作完再将其放回存储器中
只有Load和Store指令允许直接在内存和通用寄存器之间进行数据的读取和存储,其他例如算数和逻辑运算指令主要在通用寄存器之间进行,不直接涉及内存。有助于简化指令集结构,提高指令执行效率
ARM指令的三地址指令格式与条件执行
三地址指令格式:ARM指令的三地址格式是指指令中含有目的操作数地址,第一源操作数地址,第二源操作数地址,根据源操作数地址得到源操作数进行运算再存到目的操作数地址;
条件执行:ARM状态下,几乎所有的指令均按照CPSR中条件码的状态以及指令中的条件域有条件地执行:条件满足时,指令执行;不满足时,指令被忽略。
交换指令SWP的特殊性
功能概述:交换指令能够在存储器和寄存器之间交换数据,常用于实现信号量操作,解决进程之间的同步与互斥关系;
特殊性体现:交换指令是一个原子操作,在并发环境中不会被中断,因此在解决信号量访问以及修改的过程中,可以用交换指令替代关中断机制实现信号量的操作,提升操作系统的执行效率。
简述RISV-V的主要特征 RISC-V,是一种基于“精简指令集(RISC)”原则的指令集架构,它具有开源、重新设计(后发优势)、简单哲学、模块化指令集、指令集可扩展的特点。
嵌入式系统最小系统的构成 CPU能够运行所需的模块有(最小系统):电源、时钟、复位、内存、调试接口
简述晶体与晶振的区别 时钟一般由晶体振荡器提供,而晶体和晶振是构成晶体振荡器的两种方式:
晶体(无源): 封装内部只含有晶体, 没有内部电源, 驱动电路由设计者提供;
晶振(有源): 封装中包含了完整的晶体振荡器电路, 需要电源
理解$\mu$cos中任务级调度与中断级调度之间的关系
关系:$\mu$cos实现的任务级调度与中断级调度是两个相互独立的机制,互不影响;
【保护任务同时可以响应中断】
程序题 C 程序与汇编程序混合编程——字符串拷贝 1 2 3 4 5 6 7 8 9 10 11 12 13 #include <stdio.h> extern void strcopy (char *d, const char *s) ;int main () { const char *srcstr = "First string-source" ; char dststr[] = "Second string-destination" ; printf ("Before copying:\n" ); printf ("%s\n%s\n" , srcstr, dststr); strcopy(dststr, srcstr); printf ("After copying:\n" ); printf ("%s\n%s\n" , srcstr, dststr); return 0 ; }
1 2 3 4 5 6 7 8 9 10 AREA scopy CODE , READONLY EXPORT strcopystrcopy LDRB R2 , [R1 ], #1 STRB R2 , [R0 ], #1 CMP R2 , #0 BNE strcopy MOV PC , LR END
LCD显示——水平直线 1 2 void PutPixel (UINT16T x, UINT16T y, UINT16T c) ;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 void Lcd_Draw_HLine (INT16T usX0, INT16T usX1, INT16T usY0, UINT16T ucColor, UINT16T usWidth) { INT16T usLen; if ( usX1 < usX0 ) { GUISWAP (usX1, usX0); } while ( (usWidth--) > 0 ) { usLen = usX1 - usX0 + 1 ; while ( (usLen--) > 0 ) { PutPixel(usX0 + usLen, usY0, ucColor); } usY0++; } }
$\mu$cos信号量任务管理——键盘识别显示 1 2 3 INT8U keyScan (void ) ; void keyPrint (INT8U x, INT8U y, INT8U c) ;
1 2 3 4 5 6 7 8 extern OS_EVENT *Keypad_Sem;void __KeyPad(void ){ INT8U err; ClearPending(BIT_EINT1); err = OSSemPost(Keypad_Sem); }
1 2 3 4 5 6 7 8 9 10 11 12 OS_EVENT *Keypad_Sem; void KeyTask (void *data) { Keypad_Sem = OSSemCreate(0 ); INT8U err, key, x = 100 , y = 100 ; while (1 ){ OSSemPend(Keypad_Sem, 0 , &err); key = keyScan(); keyPrint(x, y, key); } }
基于SWP指令的信号量访问 1 2 3 4 5 6 7 SEM EQU 0x20001000 SEM_CHECK MOV R1 , #0 LDR R0 , =SEM SWP R1 , R1 , [R0 ] CMP R1 , #0 BEQ SEM_CHECK
LED——基于GPIOB口的发光二极管设计 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #define rGPBCON (*(volatile unsigned *)0xCD74) #define rGPBDAT (*(volatile unsigned *)0xCD78) #define rGPBUP (*(volatile unsigned *)0xCD7C) void led_on_off (void ) { rGPBCON = 0x15400 ; rGPBUP = 0x7FF ; rGPBDAT = 0 ; deLay(30 ); rGPBDAT = 0x0010 ; deLay(1000 ); } int main (void ) { sys_init(); while (1 ){ led_on_off(); } }
$\mu$cos互斥管理——串口输出信息 1 2 3 4 5 6 7 8 9 10 11 12 OS_EVENT *UART_sem; void myTask (void *data) { unsigned char err; UART_sem = OSSemCreate(1 ); while (1 ){ OSSemPend(UART_sem, 0 , &err); uart_sending("I'm running now!" ); OSTimDly(30 ); OSSemPost(UART_sem); } }
程序题准备部分 多任务应用函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 #define STACKSIZE 256 OS_STK Stack[STACKSIZE]; const char Id = '1' ; INT8U OSTaskCreate (void (*task)(void *pd), void *pdata, OS_STK *ptos, INT8U prio) ; INT8U OSTaskDel (INT8U prio) ; OSTaskDel(OS_PRIO_SELF); void OSStart (void ) ;INT8U OSTaskChangePrio (INT8U oldprio, INT8U newprio) ; INT8U OSTaskSuspend (INT8U prio) ; INT8U OSTaskResume (INT8U prio) ; void OSTimeDly (INT16U ticks) ;INT8U OSTimeDlyResume (INT8U prio) ;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 OS_EVENT *UART_sem; unsigned char err; #define STACKSIZE 256 OS_STK Stack1[STACKSIZE]; OS_STK Stack2[STACKSIZE]; OS_STK StackMain[STACKSIZE]; const char Id1 = '1' ;const char Id2 = '2' ;void Task1 (void *Id) { while (1 ){ OSSemPend(UART_sem, 0 , &err); uart_sendstring("Task1 Called.\r\n" ); OSTimeDly(50 ); OSSemPost(UART_sem); } } void Task2 (void *Id) { while (1 ) { OSSemPend(UART_sem, 0 , &err); uart_sendstring("Task2 Called.\r\n" ); OSSemPost(UART_sem); } } void TaskStart (void *Id) { UART_sem = OSSemCreate(1 ); OSTaskCreate(Task1, (void *)&Id1, &Stack1[STACKSIZE - 1 ], 2 ); OSTaskCreate(Task2, (void *)&Id2, &Stack2[STACKSIZE - 1 ], 3 ); OSTaskDel(OS_PRIO_SELF); } void Main (void ) { OSInit(); OSTimeSet(0 ); OSTaskCreate(TaskStart,(void *)0 , &StackMain[STACKSIZE - 1 ], 0 ); OSStart(); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 INT8U Task1Data, Task2Data; INT8U Task1prio=1 , Task2prio=2 ; #define STACKSIZE 256 OS_STK Task1Stk[STACKSIZE]; OS_STK Task1Stk[STACKSIZE]; void Task1 (void ) { while (1 ){ Task1Data++; OSTimeDly(25 ); } } void Task2 (void ) { while (1 ) { Task2Data++; OSTimeDly(50 ); } } void main () { OSInit (); OSTaskCreate(Task1, (void *)&Task1Data, (void *)&Task1Stk[STACKSIZE-1 ], Task1prio); OSTaskCreate(Task2, (void *)&Task2Data, (void *)&Task2Stk[STACKSIZE-1 ],Task2prio); OSStart(); }
信号量应用函数 1 2 3 4 5 6 7 8 9 10 11 OS_EVENT *pevent; OS_EVENT *OSSemCreate (INT16U cnt) ; void OSSemPend (OS_EVENT *pevent, INT16U timeout, INT8U *err) ; INT8U OSSemPost (OS_EVENT *pevent) ; OS_EVENT *pevent; unsigned char err;OSSemPend(pevent, 0 , &err); err = OSSemPost(pevent);
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 #define TaskStkLeath 128 OS_STK TestTask1Stk[TaskStkLeath]; OS_STK TestTask2Stk[TaskStkLeath]; OS_EVENT *sem1; OS_EVENT *sem2; unsigned char err;void Task1 (void *pdata) { while (1 ) { OSSemPend(sem1, 0 , &err); uart_sendstring("Now task1 is running!\r\n" ); OSTimeDly(30 ); uart_sendstring("Task1 resumed task2!\r\n" ); OSSemPost(sem2); } } void Task2 (void *pdata) { while (1 ) { OSSemPend(sem2, 0 , &err); uart_sendstring("Now task2 is running!\r\n" ); OSTimeDly(30 ); uart_sendstring("Task2 resumed task1!\r\n" ); OSSemPost(sem1); } } void Main (void ) { OSInit(); sem1 = OSSemCreate(1 ); sem2 = OSSemCreate(0 ); OSTaskCreate(Task1,(void *)1 ,&TestTask1Stk[TaskStkLeath-1 ],5 ); OSTaskCreate(Task2,(void *)2 ,&TestTask2Stk[TaskStkLeath-1 ],6 ); OSStart(); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 #define TaskStkLeath 128 OS_EVENT *UART_sem; unsigned char err;OS_STK TestTask1Stk[TaskStkLeath]; OS_STK TestTask2Stk[TaskStkLeath]; void Task1 (void *pdata) { while (1 ) { OSSemPend(UART_sem, 0 , &err); uart_sendstring("Task1: i will Suspend by myself\r\n" ); OSSemPost(UART_sem); OSTaskSuspend(2 ); OSSemPend(UART_sem, 0 , &err); uart_sendstring("Task1: i Resumed by Task2\r\n" ); OSSemPost(UART_sem); OSTimeDly(10 ); } } void Task2 (void *pdata) { while (1 ) { OSSemPend(UART_sem, 0 , &err); uart_sendstring("Task2: i am executing\r\n" ); OSSemPost(UART_sem); if ( OSTaskResume(2 ) == OS_ERR_NONE ) { OSSemPend(UART_sem, 0 , &err); uart_sendstring("Task2: i Resumed Task1\n" ); OSSemPost(UART_sem); } OSTimeDly(5 ); } } void Main (void ) { OSInit(); UART_sem = OSSemCreate(1 ); OSTaskCreate(Task1,(void *)1 ,&TestTask1Stk[TaskStkLeath-1 ],2 ); OSTaskCreate(Task2,(void *)2 ,&TestTask2Stk[TaskStkLeath-1 ],1 ); OSStart(); }
互斥型信号量应用函数 1 2 3 4 5 6 7 8 9 10 11 12 OS_EVENT *pevent; OS_EVENT *OSMutexCreate (INT8U prio, INT8U *err) ; void OSMutexPend (OS_EVENT *pevent, INT16U timeout, INT8U *err) ; INT8U OSMutexPost (OS_EVENT *pevent) ; OS_EVENT *pevent; INT8U err; prevent = OSMutexCreate(2 , &err); OSMutexPend(pevent, 0 , &err); err = OSMutexPost(pevent);
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 #define TaskStkLeath 128 OS_EVENT *UART_sem; unsigned char err;OS_STK TestTask1Stk[TaskStkLeath]; OS_STK TestTask2Stk[TaskStkLeath]; void Task1 (void *pdata) { while (1 ) { OSMutexPend(UART_sem, 0 , &err); uart_sendstring("Task1: i will Suspend by myself\r\n" ); OSMutexPost(UART_sem); OSTimeDly(10 ); } } void Task2 (void *pdata) { while (1 ) { OSMutexPend(UART_sem, 0 , &err); uart_sendstring("Task2: i am executing\r\n" ); OSMutexPost(UART_sem); OSTimeDly(5 ); } } void Main (void ) { OSInit(); UART_sem = OSMutexCreate(1 , &err); OSTaskCreate(Task1,(void *)1 ,&TestTask1Stk[TaskStkLeath-1 ],2 ); OSTaskCreate(Task2,(void *)2 ,&TestTask2Stk[TaskStkLeath-1 ],3 ); OSStart(); }
LCD显示屏相关函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 void lcd_clr_rect (INT16T usLeft, INT16T usTop, INT16T usRight, INT16T usBottom, UINT16T ucColor) { UINT32T i, j; for (i = usLeft; i < usRight; i++) for (j = usTop; j < usBottom; j++) { PutPixel_16Bit_320240(i, j, ucColor); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 void Lcd_Draw_HLine (INT16T usX0, INT16T usX1, INT16T usY0, UINT16T ucColor, UINT16T usWidth) { INT16T usLen; if ( usX1 < usX0 ) { GUISWAP (usX1, usX0); } while ( (usWidth--) > 0 ) { usLen = usX1 - usX0 + 1 ; while ( (usLen--) > 0 ) { PutPixel_16Bit_320240(usX0 + usLen, usY0, ucColor); } usY0++; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 void Lcd_Draw_VLine (INT16T usY0, INT16T usY1, INT16T usX0, UINT16T ucColor, UINT16T usWidth) { INT16T usLen; if ( usY1 < usY0 ) { GUISWAP (usY1, usY0); } while ( (usWidth--) > 0 ) { usLen = usY1 - usY0 + 1 ; while ( (usLen--) > 0 ) { PutPixel_16Bit_320240(usX0, usY0 + usLen, ucColor); } usX0++; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 void Lcd_Draw_Box (INT16T usLeft, INT16T usTop, INT16T usRight, INT16T usBottom, UINT16T ucColor) { Lcd_Draw_HLine(usLeft, usRight, usTop, ucColor, 1 ); Lcd_Draw_HLine(usLeft, usRight, usBottom, ucColor, 1 ); Lcd_Draw_VLine(usTop, usBottom, usLeft, ucColor, 1 ); Lcd_Draw_VLine(usTop, usBottom, usRight, ucColor, 1 ); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 void Lcd_Draw_Line (INT16T usX0, INT16T usY0, INT16T usX1, INT16T usY1, UINT16T ucColor, UINT16T usWidth) { INT16T usDx; INT16T usDy; INT16T y_sign; INT16T x_sign; INT16T decision; INT16T wCurx, wCury, wNextx, wNexty, wpy, wpx; if ( usY0 == usY1 ) { Lcd_Draw_HLine (usX0, usX1, usY0, ucColor, usWidth); return ; } if ( usX0 == usX1 ) { Lcd_Draw_VLine (usY0, usY1, usX0, ucColor, usWidth); return ; } usDx = abs (usX0 - usX1); usDy = abs (usY0 - usY1); if ( ((usDx >= usDy && (usX0 > usX1)) || ((usDy > usDx) && (usY0 > usY1))) ) { GUISWAP(usX1, usX0); GUISWAP(usY1, usY0); } y_sign = (usY1 - usY0) / usDy; x_sign = (usX1 - usX0) / usDx; if ( usDx >= usDy ) { for ( wCurx = usX0, wCury = usY0, wNextx = usX1, wNexty = usY1, decision = (usDx >> 1 ); wCurx <= wNextx; wCurx++, wNextx--, decision += usDy ) { if ( decision >= usDx ) { decision -= usDx; wCury += y_sign; wNexty -= y_sign; } for ( wpy = wCury - usWidth / 2 ; wpy <= wCury + usWidth / 2 ; wpy++ ) { PutPixel_16Bit_320240(wCurx, wpy, ucColor); } for ( wpy = wNexty - usWidth / 2 ; wpy <= wNexty + usWidth / 2 ; wpy++ ) { PutPixel_16Bit_320240(wNextx, wpy, ucColor); } } } else { for ( wCurx = usX0, wCury = usY0, wNextx = usX1, wNexty = usY1, decision = (usDy >> 1 ); wCury <= wNexty; wCury++, wNexty--, decision += usDx ) { if ( decision >= usDy ) { decision -= usDy; wCurx += x_sign; wNextx -= x_sign; } for ( wpx = wCurx - usWidth / 2 ; wpx <= wCurx + usWidth / 2 ; wpx++ ) { PutPixel_16Bit_320240(wpx, wCury, ucColor); } for ( wpx = wNextx - usWidth / 2 ; wpx <= wNextx + usWidth / 2 ; wpx++ ) { PutPixel_16Bit_320240(wpx, wNexty, ucColor); } } } }
ARM汇编程序设计 1 2 3 4 5 int g (int a, int b, int c, int d ,int e) { return a + b + c + d + e; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 TITLE 汇编函数中调用C函数实现加:a+2 a+3 a+4 a+5 a, a=12 EXPORT f AREA f, CODE , READONLY IMPORT g STR lr , [sp , #-4 ]! MOV r0 , #12 ADD r1 , r0 , r0 ADD r2 ,r1 ,r0 ADD r3 ,r1 ,r2 STR r3 , [sp , #-4 ]! ADD r3 , r1 , r1 BL g ADD sp , sp , #4 LDR pc , [sp ], #4 END
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 TITLE 子程序调用示例AREA Init, CODE , READONLY ENTRY start MOV R0 , #10 MOV R1 , #30 BL subname return MOV R2 , R0 ... subname ADD R0 , R0 , R1 MOV PC , LR END
1 2 3 4 5 6 7 8 9 10 11 int gcd (int a , int b) { while (a!=b){ if (a>b) a=a-b; else b=b-a; } return a; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 TITLE 求最大公约数——Version1AREA gcd, CODE , READONLY ALIGN =3 ENTRY start CMP R0 , R1 BEQ stop BLT less SUB R0 , R0 , R1 B start less SUB R1 , R1 , R0 B start stop NOP MOV PC , LR
1 2 3 4 5 6 7 8 9 TITLE 求最大公约数——Version2[条件执行]AREA gcd, CODE , READONLY ALIGN =3 ENTRY start CMP R0 , R1 SUBGT R0 , R0 , R1 SUBLT R1 , R1 , R0 BNE start MOV PC , LR
1 2 if (a==0 || b==1 ) c = d + e;
1 2 3 4 CMP R0 , #0 CMPNE R1 , #1 ADDEQ R2 , R3 , R4
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 TITLE 数据块复制AREA Block, CODE , READONLY num EQU 20 ENTRY start LDR r0 , =src LDR r1 , =dst MOV r2 , #num MOV sp , #0x400 Blockcopy MOVS r3 , r2 , LSR #3 BEQ Copywords STMFD sp !, {r4 -r11 } Octcopy LDMIA r0 !, {r4 -r11 } STMIA r1 !,{r4 -r11 } SUBS r3 , r3 , #1 BNE Octcopy LDMFD sp !, {r4 -r11 } Copywords ANDS r2 , r2 , #7 BEQ Stop Wordcopy LDR r3 , [r0 ], #4 STR r3 , [r1 ], #4 SUBS r2 , r2 , #1 BNE Wordcopy Stop MOV r0 , #0x18 LDR r1 , =0x20026 SWI 0x123456 AREA BlockData, DATA , READWRITE Src DCD 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 1 , 2 , 3 , 4 Dst DCD 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 END
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 TITLE 跳转表实现程序跳转AREA Jump, CODE , READONLY num EQU 2 ENTRY Start MOV r0 , #0 MOV r1 , #3 MOV r2 , #2 BL arithfunc Stop MOV r0 , #0x18 LDR r1 , =0x20026 SWI 0x123456 Arithfunc CMP r0 , #num MOVHS pc , lr ADR r3 , JumpTable LDR pc , [r3 , r0 , LSL #2 ] JumpTable DCD DoAdd DCD DoSub DoAdd ADD r0 , r1 , r2 MOV pc , lr DoSub SUB r0 , r1 , r2 MOV pc , lr END
自主可控嵌入式系统总结文档
本章节主要是对学习笔记整理出的 PDF 文档,方便查阅。
后记
自主可控嵌入式系统随课实验 实验一 基于华为鲲鹏云服务器的 ARM 开发
实验二 基于 S3C2410 的基本接口实验
实验三 基于液晶显示屏的人机接口实验
实验四 $\mu$C/OS-II 系统原理实验
实验五 简易计算器设计
Contributors
References