项目环境安装 ESP-IDF安装 ESP-IDF 5.0+ 的版本有较大改动,在部署过程中会出现一些问题,建议使用 4.4 版本的进行安装。https://dl.espressif.com/dl/esp-idf/ . 按照流程完成安装即可。
开发环境 本项目整体开发环境主要基于训练框架,以及对应esp32的模型部署框架,具体如下:
训练、转换模型: Model Assistant
模型部署: sscma-example-esp32(1.0.0)
运行环境 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 python3.10 + CUDA11.7 + esp-idf 4.4 torch 2.0 .0 +cu117 torchaudio 2.0 .1 +cu117 torchvision 0.15 .1 +cu117 yapf 0.40 .2 typing_extensions 4.5 .0 tensorboard 2.13 .0 tensorboard-data-server 0.7 .2 tensorflow 2.13 .0 keras 2.13 .1 tensorflow-estimator 2.13 .0 tensorflow-intel 2.13 .0 tensorflow-io-gcs-filesystem 0.31 .0 sscma 2.0 .0 rc3 setuptools 60.2 .0 rich 13.4 .2 Pillow 9.4 .0 mmcls 1.0 .0 rc6 mmcv 2.0 .0 mmdet 3.0 .0 mmengine 0.10 .1 mmpose 1.2 .0 mmyolo 0.5 .0
conda 的环境依赖主要见上面各种库的版本,其中
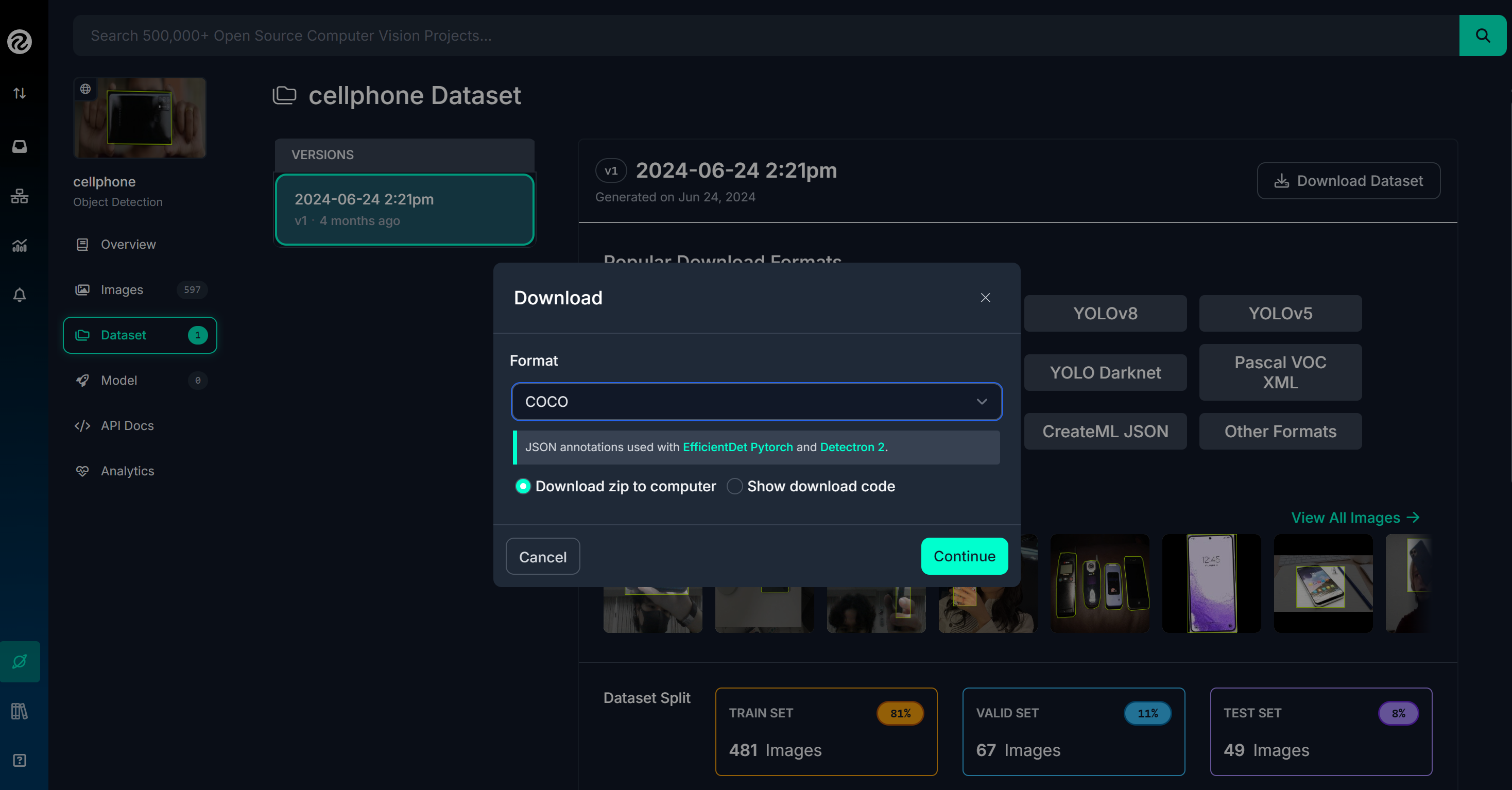
训练数据集准备 添加自定义数据集 主要的数据集可以从开源的 Roboflow Universe 搜集,比如我们需要识别某些类别,可以在该网站上下载对应的数据集,下载格式选择 COCO 格式,如下图所示:
将下载的数据集压缩包放置在 data/collection 目录下面,对各个类别数据集加压并重命名为类别名称,例如 “face”, “phone”,即类别标签。
挑选多个类别数据集后(这里选取 “face, phone”),需要对其进行合并,利用下述代码进行合并(主要合并 json 文件,并拷贝各类别数据集的图像文件 ):
prepare.py 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 import osimport jsonimport shutiltrain_path = 'datasets/collection/train' valid_path = 'datasets/collection/valid' if not os.path.exists(train_path): os.makedirs(train_path) if not os.path.exists(valid_path): os.makedirs(valid_path) def Add_Class_COCO_Data (dataset_path, classname, dataset, dataset_info ): with open (os.path.join(dataset_path, '_annotations.coco.json' ), 'r' ) as file: class_data = json.load(file) class_exist, class_id = False , None for item in dataset['categories' ]: if item['name' ] == classname: class_exist, class_id = True , item['id' ] if class_exist is False : class_id = dataset_info['category_id' ] dataset['categories' ].append({'id' : class_id, 'name' : classname}) dataset_info['category_id' ] += 1 image_id = dataset_info['img_id' ] for image in class_data['images' ]: image_info = {'id' : dataset_info['img_id' ], 'file_name' : image['file_name' ], 'width' : image['width' ], 'height' : image['height' ]} dataset['images' ].append(image_info) dataset_info['img_id' ] += 1 for ann in class_data['annotations' ]: ann_info = {'id' : dataset_info['ann_id' ], 'image_id' : image_id+ann['image_id' ], 'category_id' : class_id, 'bbox' : ann['bbox' ], 'area' : ann['area' ], 'iscrowd' : ann['iscrowd' ]} dataset['annotations' ].append(ann_info) dataset_info['ann_id' ] += 1 def Copy_Files (src_dir, dst_dir, skip_files=['_annotations.coco.json' ] ): """ Copy the files from source directory to the destination directory. """ os.makedirs(dst_dir, exist_ok=True ) for file_name in os.listdir(src_dir): if file_name in skip_files: continue src_file = os.path.join(src_dir, file_name) dst_file = os.path.join(dst_dir, file_name) if os.path.isfile(src_file): shutil.copy(src_file, dst_file) print (f"Copied: {src_file} -> {dst_file} " ) else : print (f"Skipping directory: {src_file} " ) classes = ["face" , "phone" ] category_id = 0 train_data = {'categories' : [], 'images' : [], 'annotations' : []} train_info = {'category_id' : 0 , 'img_id' : 0 , 'ann_id' : 0 } valid_data = {'categories' : [], 'images' : [], 'annotations' : []} valid_info = {'category_id' : 0 , 'img_id' : 0 , 'ann_id' : 0 } class_data_root = './data/collection' for cls_name in classes: class_train_path = os.path.join(class_data_root, cls_name, 'train' ) class_valid_path = os.path.join(class_data_root, cls_name, 'valid' ) Add_Class_COCO_Data(class_train_path, cls_name, train_data, train_info) Add_Class_COCO_Data(class_valid_path, cls_name, valid_data, valid_info) Copy_Files(class_train_path, train_path) Copy_Files(class_valid_path, valid_path) with open (os.path.join(train_path, '_annotations.coco.json' ), 'w' ) as f: json.dump(train_data, f, indent=4 ) with open (os.path.join(valid_path, '_annotations.coco.json' ), 'w' ) as f: json.dump(valid_data, f, indent=4 ) print (f">>> length of categories: {len (train_data['categories' ])} " )print (f">>> length of train_data: {len (train_data['images' ])} " )print (f">>> length of valid_data: {len (valid_data['images' ])} " )
合并后的统一的训练和验证数据集全部放在了 datasets/collection 目录下面,以便于后续模型训练使用。
下载预训练模型 参考 Face Detection - Swift-YOLO 下载预训练模型权重文件 pretrain.pth ,然后保存在 ModelAssistant/checkpoints 文件夹下。
训练 YOLO 模型 在 ModelAssistant 项目下,采用的是仓库提供的 Swift YOLO 模型,作者解释说明该模型具有优化的端侧运行性能:”We implemented a lightweight object detection algorithm called Swift YOLO, which is designed to run on low-cost hardware with limited computing power. The visualization tool, model training and export command-line interface has refactored now”.
采用 swift_yolo_tiny_1xb16_300e_coco 的配置文件进行训练,训练命令如下:
1 2 3 4 5 6 7 8 9 10 python tools/train.py configs/swift_yolo/swift_yolo_tiny_1xb16_300e_coco.py \ --cfg-options \ work_dir=work_dirs/collection \ num_classes=2 \ epochs=300 \ height=96 \ width=96 \ data_root=datasets/collection/ \ load_from=checkpoints/pretrain.pth
模型量化和格式转换 训练完毕后,还需要对模型进行权重量化以及格式转换,这样才能够让模型成功在 ESP32S3 主板上运行。在工作目录 work_dirs/collection 下,找到最好的 bbox_mAP 的模型,例如这里是 best_coco_bbox_mAP_epoch_300.pth,采用以下命令导出模型:
1 2 3 4 5 6 7 8 9 python tools/export.py configs/swift_yolo/swift_yolo_tiny_1xb16_300e_coco.py ./work_dirs/collection/best_coco_bbox_mAP_epoch_300.pth --cfg-options \ work_dir=work_dirs/collection \ num_classes=2 \ epochs=300 \ height=96 \ width=96 \ data_root=datasets/collection/ \ load_from=checkpoints/pretrain.pth
导出的模型会保存在 work_dirs/collection 文件夹下,生成 best_coco_bbox_mAP_epoch_300_int8.tflite 文件,这是量化到 Int8 格式的 tflite 文件,可以用于后续模型的部署。
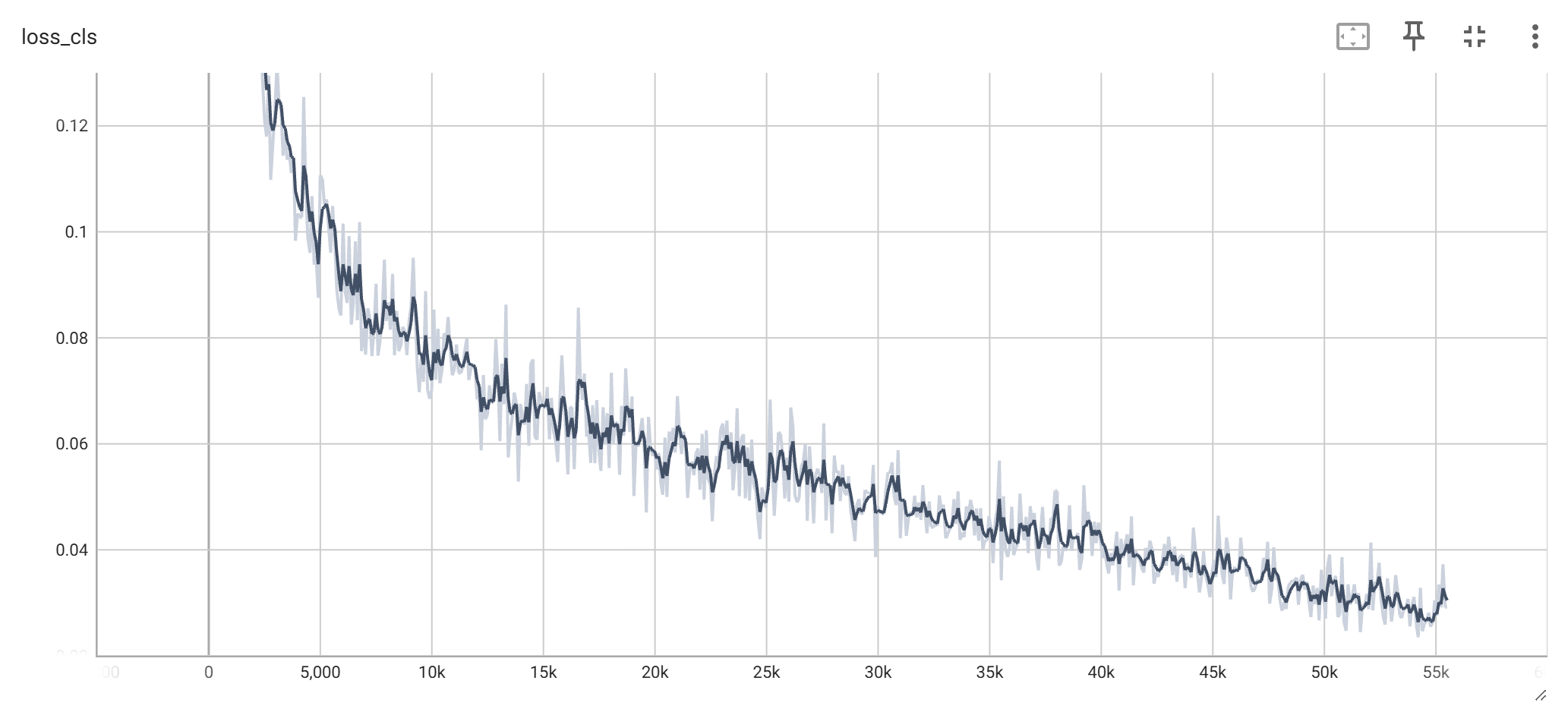
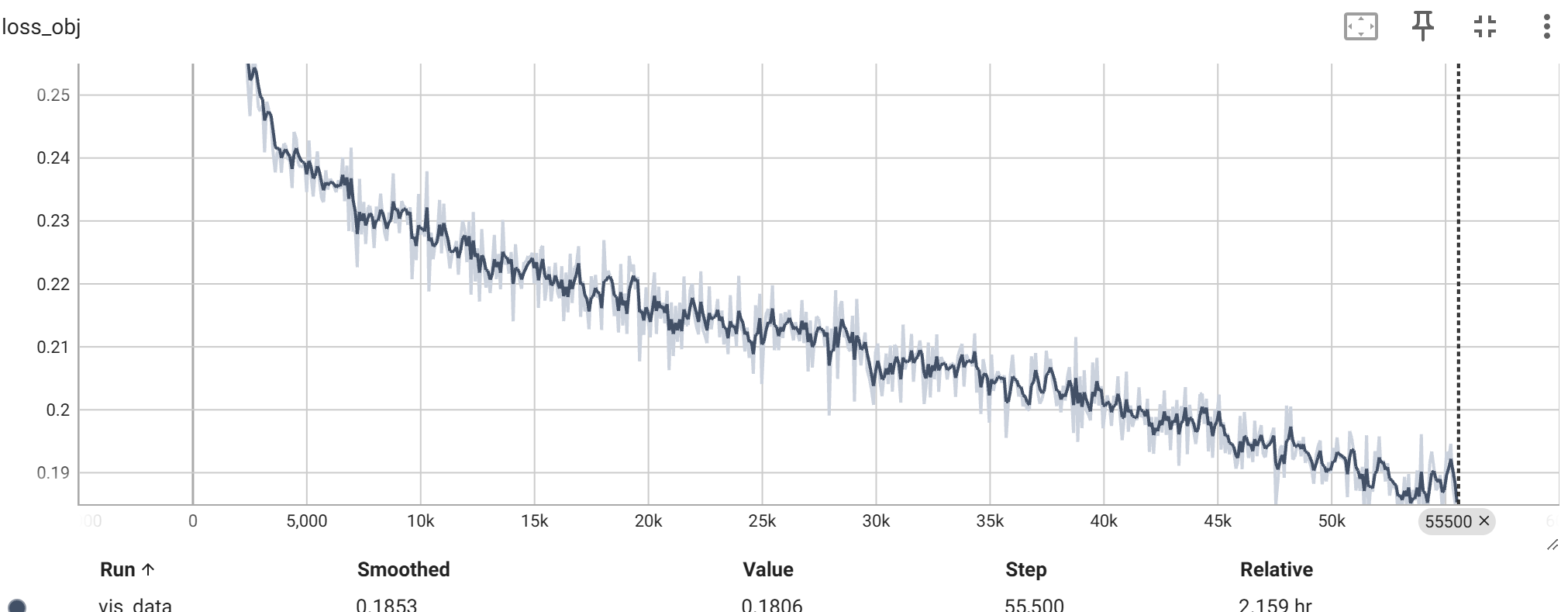
模型结果评估 训练损失 在整个 300 epoches 的训练过程中,对应的类别损失以及目标检测损失的变化如下图所示:
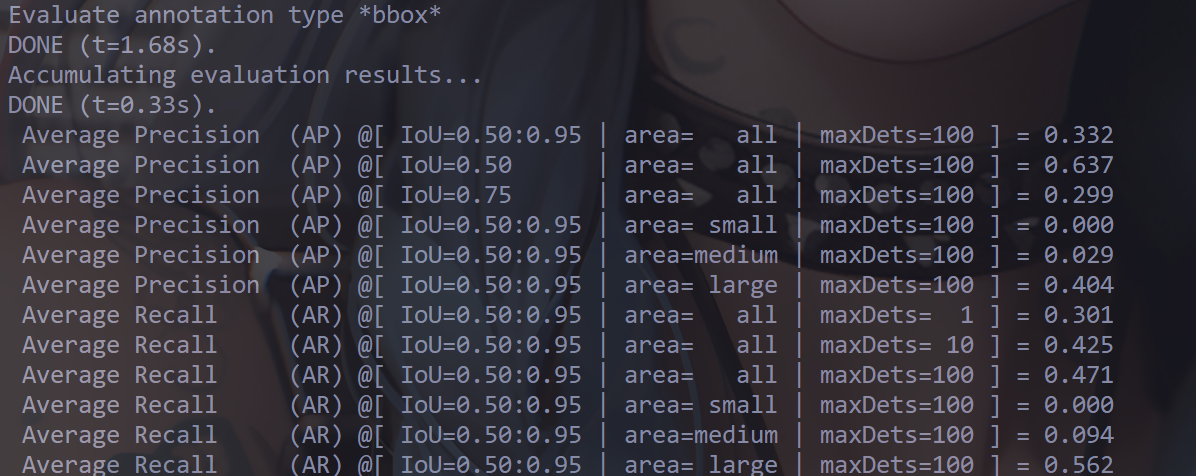
评估指标 在该项目中,主要测定了 Swift YOLO Tiny 结构以及 Swift YOLO Tiny Nano 结构(一种高度紧凑的深卷积神经网络,用于使用人机协同设计策略设计的嵌入式目标检测),主要的评估指标如下所示:
考虑到部署到端侧设备上时,更关注于目标检测的置信度,因此下面主要从置信度、平均推理时间的角度进行评估。
可以看到,模型量化压缩后在能够维持较高的精度的情况下,模型大小显著减小,但是推理时间并没有降低,甚至约有增加;
Swift YOLO Tiny Nano 的精度更高,但是模型大小更大,推理时间更长,在 ESP32S3-EYE 设备上牺牲的代价就是帧率较低;
整体而言,模型的置信度都已经比较高以及推理速度能比较不错,能够满足实际应用需求。
此外,我还尝试了保持原图像尺寸,即对于Swift YOLO Tiny配置而言,设置模型处理的图像宽高都是640,具体如下:
1 2 3 4 5 6 7 8 9 10 python tools/train.py configs/swift_yolo/swift_yolo_tiny_1xb16_300e_coco.py \ --cfg-options \ work_dir=work_dirs/collection_640 \ num_classes=2 \ epochs=300 \ height=640 \ width=640 \ data_root=datasets/collection/ \ load_from=checkpoints/pretrain.pth
训练后模型的评估指标如下所示:
虽然整体的精度有所提升,但是推理时间显著增加,模型虽然大小基本维持不变,但是推理时间增大了将近10倍,处理图像的分辨率所带来的开销远远超过了模型识别的精度。事实上,Swift YOLO Tiny WH640 在 ESP32S3-EYE 设备上已经没办法运行,实际中会出现数据存储栈溢出的问题,摄像头采集的图像分辨率太高导致栈空间不足。
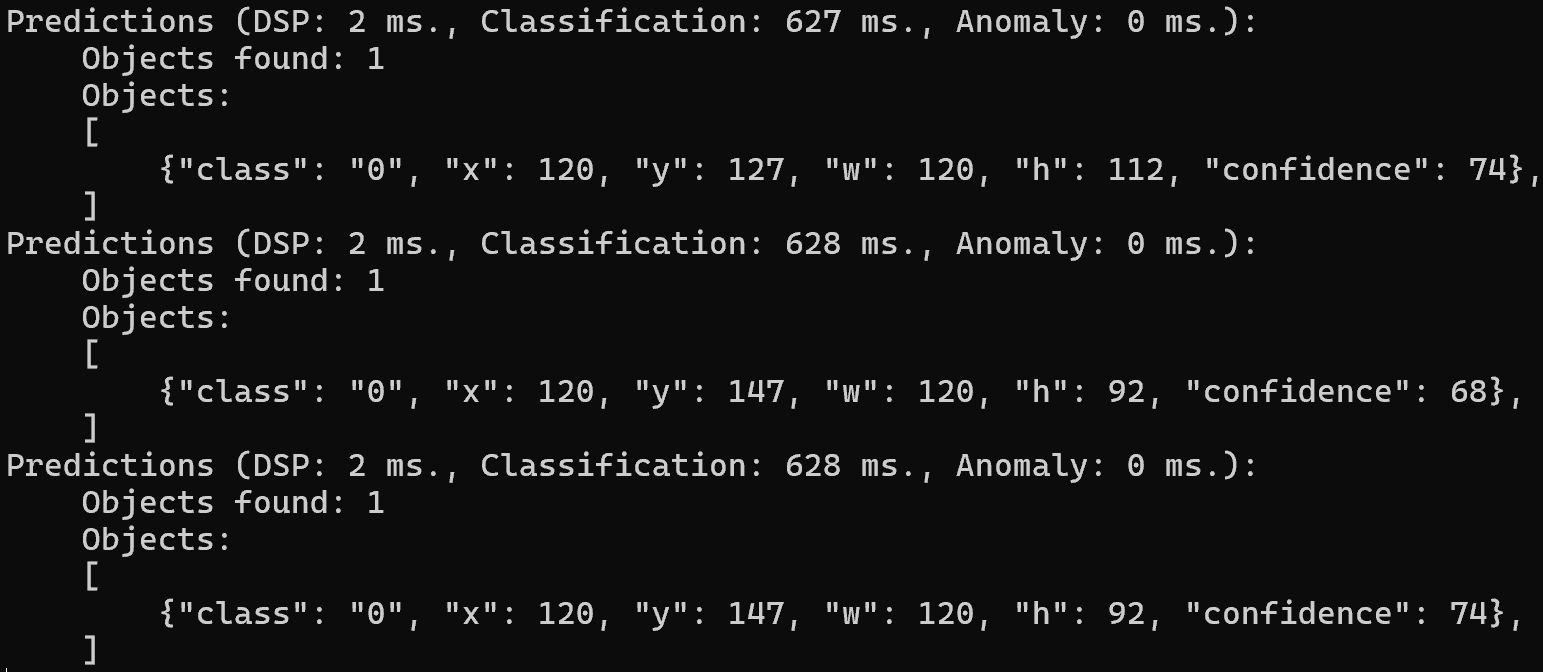
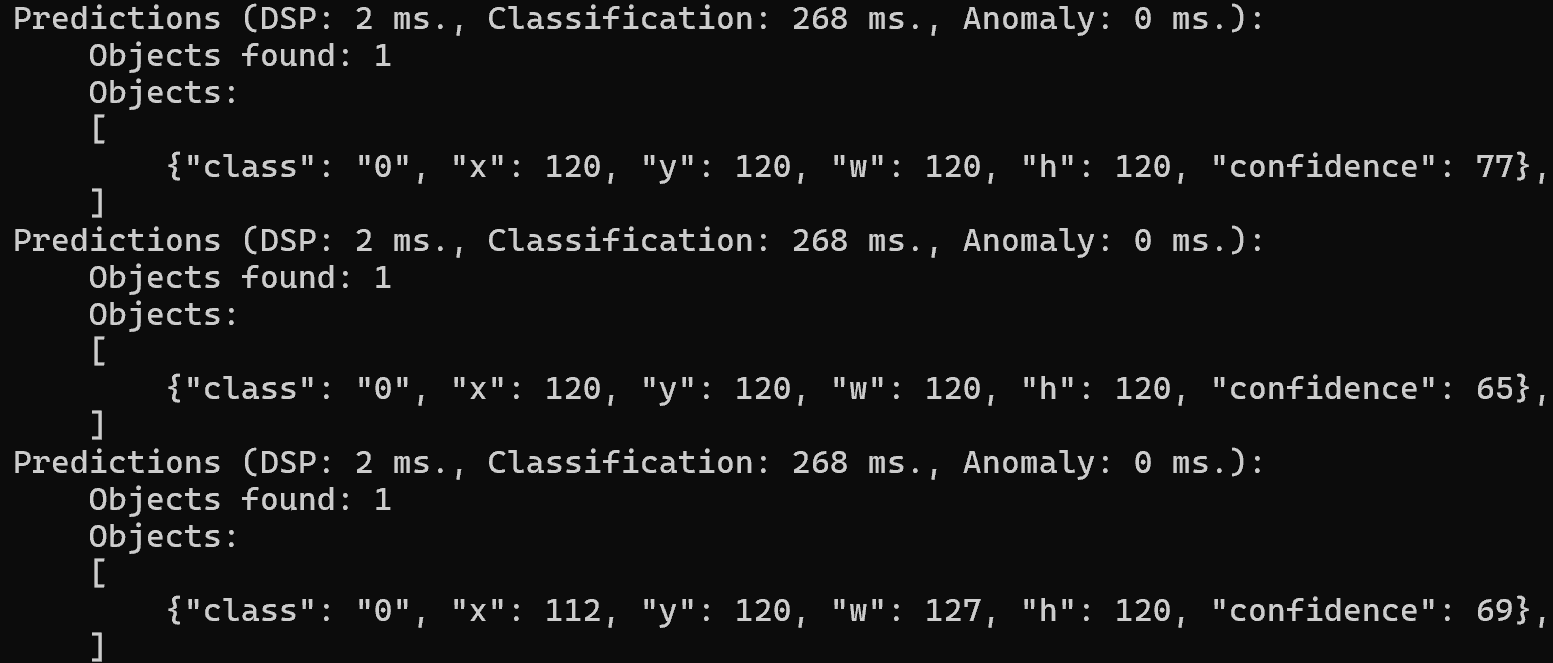
模型推理 主要是观测量化后模型对验证集的推理结果,具体如下:
模型部署 部署环境 部署环境为 ESP32-S3 EYE 开发板,没判断错的话,它有 4MB Flash,我们烧录的模型也主要存储在这个区域,当然它也附带了 SD 卡功能,可以从 SD 卡中加载模型。4 MB 的 Flash 分配主要在 partitions.csv 文件中,具体如下:
partitions.csv 1 2 3 4 5 # Name Type SubType Offset Size Flags # Note: if you change the phy_init or app partition offset make sure to change the offset in Kconfig.projbuild factory app factory 0x010000 2048K nvs data nvs 0x3D0000 64K fr data 0x3E0000 128K
默认 app 分区最多有 2048K 即 2MB 的大小,但是由于地址空间还很充裕,例如从 0x010000 到 0x3D0000 的大小,最多可以分配 3MB 的空间,足够上述量化后的模型存储。此外,分区表主要以 64KB 为单位分配的,所以偏移地址后四位都为0. 可以在项目中通过 idf.py build 查看输出信息,其中包含了对分区大小是否合适以及剩余空间的判断。
对于 Swift YOLO Tiny Nano 配置,需要将分区表中的 app 分区增大到 3MB 即 3072K.
导入模型 对于烧录程序而言,需要将 tflite 格式模型转换为 c 语言格式,具体在项目 sscma-example-esp32-1.0.0 中,通过 tools/tflite2c.py 文件进行转换,但是为了能够在显示屏上同步显示检测的类别名称,需要修改其中的代码,即将 classes 换成字符串,然后通过分词找到各个类别,并将其转换为字符串列表,其中每个字符串都是一个类别名称 ,具体如下:
tools/tflite2c.py 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 import sysimport osimport binasciiimport argparsedef parse_args (): parser = argparse.ArgumentParser( description='Convert tflite to c or cpp file' ) parser.add_argument('--input' , help ='input tflite file' ) parser.add_argument('--output_dir' , help ='output directory' ) parser.add_argument('--name' , help ='model name' ) parser.add_argument('--cpp' , action='store_true' , default=True , help ='output cpp file' ) parser.add_argument('--classes' , type =str , help ='classes name' ) args = parser.parse_args() return args if __name__ == '__main__' : args = parse_args() input = args.input name = args.name output_dir = args.output_dir classes = args.classes if classes != None : classes = list (classes.split(',' )) if not os.path.exists(input ): print ('input file not exist' ) sys.exit(1 ) if name == None : name = input .split('/' )[-1 ].split('.' )[0 ] output_h = os.path.join(output_dir, name + '_model_data.h' ) if args.cpp: output_c = os.path.join(output_dir, name + '_model_data.cpp' ) else : output_c = os.path.join(output_dir, name + '_model_data.c' ) with open (input , 'rb' ) as f_input: data = f_input.read() if data[4 :8 ] != b'TFL3' : print ('input file is not tflite' ) sys.exit(1 ) data = binascii.hexlify(data) data = data.decode('utf-8' ) with open (output_h, 'w' ) as f_output_h: f_output_h.write('#ifndef __%s_MODEL_DATA_H__\r\n' % name.upper()) f_output_h.write('#define __%s_MODEL_DATA_H__\r\n' % name.upper()) f_output_h.write('\r\n//this file is generated by tflite2c.py\r\n' ) f_output_h.write('\r\n#include <stdint.h>\r\n' ) f_output_h.write( 'extern const unsigned char g_%s_model_data[];\r\n' % name) f_output_h.write( 'extern const unsigned int g_%s_model_data_len;\r\n' % name) if classes != None : f_output_h.write( 'extern const char* g_%s_model_classes[];\r\n' % name) f_output_h.write( 'extern const unsigned int g_%s_model_classes_num;\r\n' % name) f_output_h.write('\r\n#endif\r\n' ) f_output_h.close() with open (output_c, 'w' ) as f_output_c: f_output_c.write('#include <stdint.h>\r\n' ) f_output_c.write('\r\n#include "%s_model_data.h"\r\n\r\n' % name) f_output_c.write( 'const unsigned char g_%s_model_data[] = {\r\n' % name) for i in range (0 , len (data), 2 ): f_output_c.write('0x' ) f_output_c.write(data[i]) f_output_c.write(data[i+1 ]) f_output_c.write(', ' ) if i % 36 == 34 : f_output_c.write('\r\n' ) f_output_c.write('};\r\n\r\n' ) f_output_c.write( 'const unsigned int g_%s_model_data_len = %d;\r\n' % (name, len (data) // 2 )) if classes != None : f_output_c.write( 'const char* g_%s_model_classes[] = {' % name) for i in range (len (classes)): f_output_c.write('"%s", ' % classes[i]) f_output_c.write('};\r\n\r\n' ) f_output_c.write( 'const unsigned int g_%s_model_classes_num = %d;\r\n' % (name, len (classes))) else : f_output_c.write( 'const char* g_%s_model_classes[] = {};\r\n' % name) f_output_c.write( 'const unsigned int g_%s_model_classes_num = 0;\r\n' % name) f_output_c.close() f_input.close()
同时为了能够在显示屏上显示置信度,还需要在 components/modules/algorithm/algo_yolo.cpp 文件中修改相应的代码,具体如下所示:
components/modules/algorithm/algo_yolo.cpp 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 if (std::distance (_yolo_list.begin (), _yolo_list.end ()) > 0 ){ int index = 0 ; found = true ; printf (" Objects found: %d\n" , std::distance (_yolo_list.begin (), _yolo_list.end ())); printf (" Objects:\n" ); printf (" [\n" ); for (auto &yolo : _yolo_list) { yolo.x = uint16_t (float (yolo.x) / float (w) * float (frame->width)); yolo.y = uint16_t (float (yolo.y) / float (h) * float (frame->height)); yolo.w = uint16_t (float (yolo.w) / float (w) * float (frame->width)); yolo.h = uint16_t (float (yolo.h) / float (h) * float (frame->height)); fb_gfx_drawRect2 (frame, yolo.x - yolo.w / 2 , yolo.y - yolo.h / 2 , yolo.w, yolo.h, box_color[index % (sizeof (box_color) / sizeof (box_color[0 ]))], 4 ); fb_gfx_printf (frame, yolo.x - yolo.w / 2 , yolo.y - yolo.h/2 - 5 , 0x1FE0 , "%s:%d" , g_yolo_model_classes[yolo.target], yolo.confidence); printf (" {\"class\": \"%d\", \"x\": %d, \"y\": %d, \"w\": %d, \"h\": %d, \"confidence\": %d},\n" , yolo.target, yolo.x, yolo.y, yolo.w, yolo.h, yolo.confidence); index++; } printf (" ]\n" ); }
然后具体的转换命令如下所示,这将会在文件夹 components/modules/model 中生成两个文件 yolo_model_data.h 和 yolo_model_data.cpp,其中 yolo_model_data.h 中包含了模型数据的声明,yolo_model_data.cpp 中包含了模型数据的定义。
1 python tools/tflite2c.py --input ./model_zoo/facephone_96/best_coco_bbox_mAP_epoch_300_int8.tflite --name yolo --output_dir ./components/modules/model --classes "person,phone"
烧录模型 模型准备完毕后,就可以利用乐鑫的 IDF 开发工具链将模型烧录进开发板中,具体过程主要是:
使用 ESP-IDF 4.4 CMD 进入 sscma-example-esp32-1.0.0 项目的 examples/yolo 目录下;
使用 idf.py set-target esp32s3 设置目标芯片为 esp32s3;
使用 idf.py build 命令编译项目;
使用 idf.py flash monitor 命令烧录项目。
结果展示 Swift YOLO Tiny Nano 在 ESP32S3 设备上平均每张图像的处理时间是 628 ms,在端侧设备上出现帧率较低,稍微偏卡顿的效果。但是准确度提高的也不是很多,因此首选还是 Swift YOLO Tiny。
Swift YOLO Tiny 在 ESP32S3 设备上平均每张图像的处理时间是 268 ms,实时监测的帧率非常不错,已经很流畅,准确性而言也是较为不错的,具体结果如下所示:
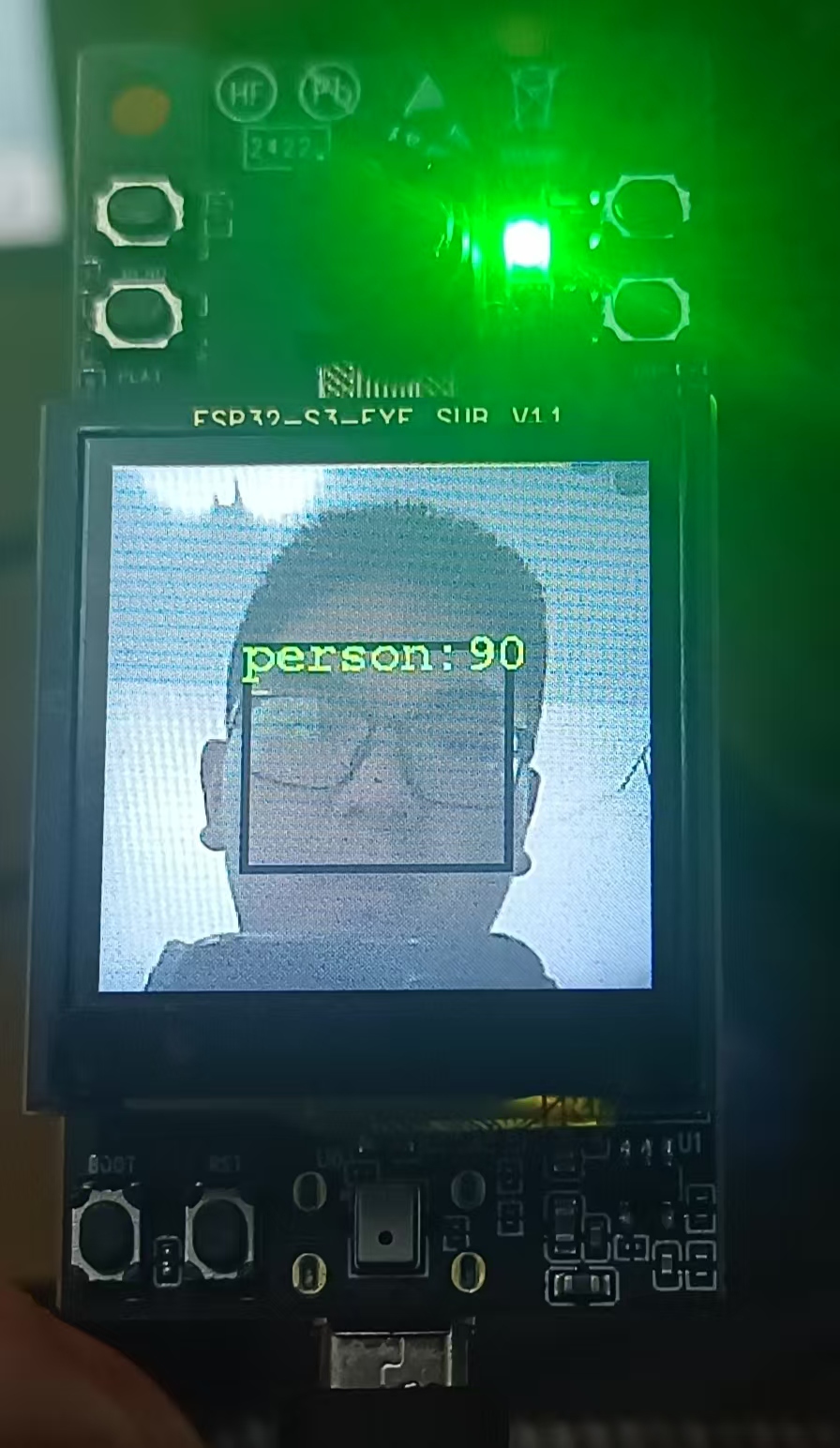
实际的开发板检测结果如下所示:
总结 本文主要介绍了如何利用 Model Assistant、sscma-example-esp32-1.0.0 项目将 YOLO 模型部署到 ESP32S3 EYE 设备上,并且通过自定义数据集实现训练、导出、转换、导入、部署模型整个流程,也对实际开发板进行了测试,最终得到了较为理想的结果。
本文主要选取了 “face, phone” 两个类别进行训练,如果需要训练更多的类别,可以添加更多的类别,但是会存在目标检测上限以及端侧设备计算性能的限制,需要进一步平衡。
References