SRRS 研究方法的探索历程
Robust Prompt Learning for Visual Language Models
实验论文:Why Is Prompt Tuning for Vision-Language Models Robust to Noisy Labels?
探索时的框架

研究背景
预训练-微调范式(Pre-Training and Fine-Tuning(PT-FT) 已经成为自然语言处理和多模态领域中的主流,针对视觉语言模型,通过提示学习微调预训练模型适配下游数据集已经被广泛地证明有非常好的泛化性能。然而对于许多下游任务场景,获取的数据往往具有很大的噪声,采用的人工标注和校正方法将会耗费大量时间成本,并且针对模型快速迁移应用的需求,我们旨在探索一种对噪声鲁棒性更强并且采用少样本学习的鲁棒性提示学习机制,能够更好地微调视觉语言模型适配到下游数据集。
研究领域
- Noisy Label Learning
- Few-shots Learning
- Prompt Learning
- Visual Language Models(VLMs)
研究基础
- 数据:下游任务数据集存在噪声(标注错误);
- 模型:Visual Language Models (VLMs);
- 目标:在有噪音的下游任务上学习一个 Robust 的模型;
- 方式:fine-tune pre-trained model,few-shots learning;
相关工作
PTNL, Robust To Noisy Labels^[1]^
Findings
- 固定的类 Tokens 对模型优化能够提供强有力的约束作用;
- 提示学习能够抑制噪声样本的梯度更新;
- 预训练的图像文本嵌入为图像分类提供了强有力的先验知识;
Conclusions
- CLIP 本身具有一定的噪声鲁棒性;
- CLIP 对下游任务具有强有力的先验知识;
JoAPR, Joint Adaptive Partitioning for Label Refurbishment^[2]^
Findings
- 第一篇提出面向VL-PTM提示学习的解决标签噪声的系统解决方案;
- 设计联合自适应阈值用于干净和噪声样本筛选;
Methods

- 利用EM算法对样本的预测损失,建立GMM模型,并引入了两个自适应阈值,$\theta_1,\theta_2$
- 其中 $\theta_1$ 用于控制GMM拟合出的干净与噪声样本损失分布的最佳分界点,是固定的;
- 其中 $\theta_2$ 用于控制模型学习能力,用当前 epoch 下筛选为噪声样本比率控制下一个 epoch 的样本筛选阈值;
- 最后对干净和噪声样本做标签翻新,均采用了数据增强;
[1] C. Wu et al. Why Is Prompt Tuning for Vision-Language Models Robust to Noisy Labels? In ICCV, 2023.
[2] Guo. Gu et al. JoAPR: Cleaning the lens of prompt learning for vision-language models. In CVPR, 2024.
研究思路——生成与判别伪标签
多分类器
Prompts 设置
- 对每一个 class 设置噪声样本提示与干净样本提示,即
- [< a clean photo of > < class >]
- [< a noisy photo of > < class >]
Framework

实验结果
| Method | Dataset | Noise Rate | Noise Rate | Noise Rate | Noise Rate | Noise Rate | Noise Rate | Noise Rate |
|---|---|---|---|---|---|---|---|---|
| 0 | 12.5% | 25.0% | 37.5% | 50% | 62.5% | 75.0% | ||
| Caltech101 | CoOp | 79.03% | 70.60% | 65.70% | 57.57% | 47.20% | 36.67% | |
| Caltech101 | PTNL | 90.65% | 82.51% | 78.70% | 70.13% | |||
| Caltech101 | CoOp+JoAPR | 88.50% | 89.07% | 88.47% | 89.03% | 87.67% | 84.87% | |
| Caltech101 | CoOp+JoAPR* | 89.20% | 89.30% | 89.60% | 88.83% | 87.10% | 85.20% | |
| Caltech101 | CoOp+DPL | 91.39% +- 0.24% | 90.90% +- 0.08% | 89.70% +- 0.61% | 89.66% +- 1.01% | 86.79% +- 0.27% | 81.84% +- 2.24% | 74.89% +- 4.50% |
| Dtd | CoOp | 55.50% | 49.27% | 43.83% | 36.00% | 27.23% | 19.77% | |
| Dtd | PTNL | 62.86% | 58.90% | 53.62% | 46.19% | |||
| Dtd | CoOp+JoAPR | 58.83% | 57.67% | 55.70% | 53.07% | 50.67% | 46.30% | |
| Dtd | CoOp+JoAPR* | 56.63% | 56.63% | 56.77% | 53.07% | 49.40% | 46.83% | |
| Dtd | CoOp+DPL | 63.53% +- 0.11% | 61.90% +- 0.93% | 61.21% +- 0.14% | 56.99% +- 1.17% | 55.40% +- 1.99% | 49.94% +- 0.95% | 42.00% +- 1.97% |
| Oxford_pets | CoOp | 77.67% | 69.23% | 58.73% | 48.37% | 35.37% | 22.37% | |
| Oxford_pets | PTNL | 87.89% | 84.62% | 81.20% | 73.13% | |||
| Oxford_pets | CoOp+JoAPR | 85.20% | 85.40% | 85.27% | 85.67% | 85.30% | 83.77% | |
| Oxford_pets | CoOp+JoAPR* | 85.93% | 86.13% | 85.17% | 86.27% | 84.53% | 83.10% | |
| Oxford_pets | CoOp+DPL | 89.52% +- 0.28% | 88.70% +- 0.07% | 87.81% +- 0.66% | 86.81% +- 0.65% | 85.69% +- 0.55% | 80.20% +- 1.31% | 74.92% +- 2.65% |
| Ucf101 | CoOp | 68.73% | 64.43% | 58.37% | 51.83% | 43.67% | 30.30% | |
| Ucf101 | PTNL | 73.12% | 68.73% | 67.66% | 60.93% | |||
| Ucf101 | CoOp+JoAPR | 73.90% | 73.17% | 72.77% | 70.00 % | 67.10% | 65.40% | |
| Ucf101 | CoOp+JoAPR* | 73.37% | 73.83% | 71.40% | 70.30% | 66.83% | 63.80% | |
| Ucf101 | CoOp+DPL | 74.12% +- 0.57% | 72.85% +- 0.79% | 71.68% +- 0.69% | 70.69% +- 0.57% | 68.67% +- 0.88% | 65.55% +- 0.34% | 59.19% +- 1.14% |
二分类器
Prompts 设置
- 对每一个 class 设置噪声样本提示与干净样本提示,即
- [< a photo of a > < class > < with clean label > ]
- [< a photo of a > < class > < with noisy label > ]
分析
- 功能:噪声样本提示,应当在开始的时候将 noisy label 的样本识别出来;当 noisy label 经过不断翻新,越来越接近 clean label 时,它将会重新将该样本识别成干净样本;
- 因此,必须在提示学习中引入不断改良的伪标签,另外设置一个二分类器检测改良的伪标签是否达到干净标签的水平;
- 结论:应当构建一个不断改良并生成伪标签的伪标签生成器,同时构建一个用于检测伪标签生成质量的伪标签判别器;
Framework

- 伪标签生成器不断翻新样本标签生成新的伪标签,并且希望生成的伪标签能够通过判别器的判断,即使得由生成的伪标签构造的提示学习器,会引导判别器将该样本预测为干净样本;
- 伪标签判别器对生成的伪标签进行二分类,判断该伪标签是图像的干净标签还是噪声标签,为了能够优化判别器,进一步通过构建 GMM 模型依据伪标签预测的干净概率进行划分,使得 GMM 增强干净样本和噪声样本的划分结果,指导模型进一步学习。
模型优化
- 伪标签生成器
$$
L_G = CE(1, D(G(z))), z=(x_i, y_i)
$$
- 伪标签判别器
$$
L_D = CE(\tilde{y_g}, D(x_i)=\tilde{y_c})
$$
生成器模型改进
- Prompts 设置
文本提示:[is the label of this image [$\tilde{y_i}$]?]
图像提示:图像特征 $V_i$
- Backbone: Vision-Language Model
- 功能:实现视觉问答,直接预测 Yes/No 概率


模型优化
- Prompts 设置
文本提示:[is the label of this image [$y_i$]?],其中 $y_i$ 表示原始的数据集上的噪声标签
- 生成器生成标签给判别器学习:通过GMM对损失建模,得到干净数据集和噪声数据集;
- 判别器判断原始的噪声标签是否是干净的,为生成器生成监督的标签;
- 方式一:干净使用原有标签,噪声则翻新标签;
- 方式二:干净则翻新标签,噪声使用生成器的输出;
建立二分类的 Base 模型
针对Discriminator设置的两条提示词,仍然用text encoder提取文本特征,然后依据特征相似度进行二分类,针对二分类结果判定是否是干净和噪声标签,后续进行标签交互增强。
实验结果
| Method | Dataset | Noise Rate | Noise Rate | Noise Rate | Noise Rate | Noise Rate | Noise Rate | Noise Rate |
|---|---|---|---|---|---|---|---|---|
| 0 | 12.5% | 25.0% | 37.5% | 50% | 62.5% | 75.0% | ||
| Caltech101 | CoOp | 79.03% | 70.60% | 65.70% | 57.57% | 47.20% | 36.67% | |
| Caltech101 | PTNL | 90.65% | 82.51% | 78.70% | 70.13% | |||
| Caltech101 | CoOp+JoAPR | 88.50% | 89.07% | 88.47% | 89.03% | 87.67% | 84.87% | |
| Caltech101 | CoOp+JoAPR* | 89.20% | 89.30% | 89.60% | 88.83% | 87.10% | 85.20% | |
| Caltech101 | CoOp+BiC | 89.26% +- 1.33% | 82.53% +- 7.87% | 86.06% +- 5.40% | 88.57% +- 0.76% | 85.95% +- 6.12% | 48.64% +- 34.94% | 79.08% +- 11.97% |
| Caltech101 | CoOp+DPL | 91.39% +- 0.24% | 90.90% +- 0.08% | 89.70% +- 0.61% | 89.66% +- 1.01% | 86.79% +- 0.27% | 81.84% +- 2.24% | 74.89% +- 4.50% |
| Dtd | CoOp | 55.50% | 49.27% | 43.83% | 36.00% | 27.23% | 19.77% | |
| Dtd | PTNL | 62.86% | 58.90% | 53.62% | 46.19% | |||
| Dtd | CoOp+JoAPR | 58.83% | 57.67% | 55.70% | 53.07% | 50.67% | 46.30% | |
| Dtd | CoOp+JoAPR* | 56.63% | 56.63% | 56.77% | 53.07% | 49.40% | 46.83% | |
| Dtd | CoOp+BiC | 46.59% +- 4.00% | 54.93% +- 5.57% | 54.88% +- 2.09% | 54.43% +- 0.47% | 53.55% +- 0.27% | 37.59% +- 14.40% | 16.08% +- 20.81% |
| Dtd | CoOp+DPL | 63.53% +- 0.11% | 61.90% +- 0.93% | 61.21% +- 0.14% | 56.99% +- 1.17% | 55.40% +- 1.99% | 49.94% +- 0.95% | 42.00% +- 1.97% |
| Oxford_pets | CoOp | 77.67% | 69.23% | 58.73% | 48.37% | 35.37% | 22.37% | |
| Oxford_pets | PTNL | 87.89% | 84.62% | 81.20% | 73.13% | |||
| Oxford_pets | CoOp+JoAPR | 85.20% | 85.40% | 85.27% | 85.67% | 85.30% | 83.77% | |
| Oxford_pets | CoOp+JoAPR* | 85.93% | 86.13% | 85.17% | 86.27% | 84.53% | 83.10% | |
| Oxford_pets | CoOp+BiC | 84.90% +- 3.33% | 83.07% +- 0.79% | 74.31% +- 8.84% | 82.16% +- 3.12% | 83.13% +- 0.57% | 79.69% +- 5.17% | 67.28% +- 9.42% |
| Oxford_pets | CoOp+DPL | 89.52% +- 0.28% | 88.70% +- 0.07% | 87.81% +- 0.66% | 86.81% +- 0.65% | 85.69% +- 0.55% | 80.20% +- 1.31% | 74.92% +- 2.65% |
| Ucf101 | CoOp | 68.73% | 64.43% | 58.37% | 51.83% | 43.67% | 30.30% | |
| Ucf101 | PTNL | 73.12% | 68.73% | 67.66% | 60.93% | |||
| Ucf101 | CoOp+JoAPR | 73.90% | 73.17% | 72.77% | 70.00 % | 67.10% | 65.40% | |
| Ucf101 | CoOp+JoAPR* | 73.37% | 73.83% | 71.40% | 70.30% | 66.83% | 63.80% | |
| Ucf101 | CoOp+BiC | 51.44% +- 18.32% | 44.72% +- 35.20% | 22.74% +- 34.79% | 33.62% +- 29.03% | 12.12% +- 18.04% | 13.67% +- 20.52% | 25.17% +- 21.66% |
| Ucf101 | CoOp+DPL | 74.12% +- 0.57% | 72.85% +- 0.79% | 71.68% +- 0.69% | 70.69% +- 0.57% | 68.67% +- 0.88% | 65.55% +- 0.34% | 59.19% +- 1.14% |
基于 Bert 跨模态编码器的伪标签判别器
一、重构基于 Bert 的提示学习器
基于 Bert 模型的词嵌入编码器,设置提示学习器,提示词 is the label of this image 在类别之间共享且可学习,而 CLS token 固定;
| 提示词 | 效果 |
|---|---|
| < is the label of this image > <$y_i$?> | 较差 |
| < the class label for the image is > <$y_i$.> | 较差 |
| < a photo of a ><$y_i$ with right label.> | 较好 |
二、整体框架

三、实验结果【RPL】
| Method | Dataset | Noise Rate | Noise Rate | Noise Rate | Noise Rate | Noise Rate | Noise Rate | Noise Rate |
|---|---|---|---|---|---|---|---|---|
| 0 | 12.5% | 25.0% | 37.5% | 50% | 62.5% | 75.0% | ||
| Caltech101 | CoOp | 79.03% | 70.60% | 65.70% | 57.57% | 47.20% | 36.67% | |
| Caltech101 | PTNL | 90.65% | 82.51% | 78.70% | 70.13% | |||
| Caltech101 | CoOp+JoAPR | 88.50% | 89.07% | 88.47% | 89.03% | 87.67% | 84.87% | |
| Caltech101 | CoOp+JoAPR* | 89.20% | 89.30% | 89.60% | 88.83% | 87.10% | 85.20% | |
| Caltech101 | CoOp+BiC | 89.26% +- 1.33% | 82.53% +- 7.87% | 86.06% +- 5.40% | 88.57% +- 0.76% | 85.95% +- 6.12% | 48.64% +- 34.94% | 79.08% +- 11.97% |
| Caltech101 | CoOp+DPL | 91.39% +- 0.24% | 90.90% +- 0.08% | 89.70% +- 0.61% | 89.66% +- 1.01% | 86.79% +- 0.27% | 81.84% +- 2.24% | 74.89% +- 4.50% |
| Caltech101 | CoOp+Bert | 93.85% +- 0.38% | 92.10% +- 2.30% | 88.67% +- 4.74% | 89.55% +- 5.28% | 88.06% +- 6.00% | 86.23% +- 5.13% | 81.97% +- 8.37% |
| Caltech101 | CoOp+BertClean | 94.24% +- 0.10% | 94.75% +- 0.32% | 94.55% +- 0.34% | 93.96% +- 0.78% | 94.20% +- 0.44% | 93.50% +- 0.88% | 92.33% +- 0.33% |
| Dtd | CoOp | 55.50% | 49.27% | 43.83% | 36.00% | 27.23% | 19.77% | |
| Dtd | PTNL | 62.86% | 58.90% | 53.62% | 46.19% | |||
| Dtd | CoOp+JoAPR | 58.83% | 57.67% | 55.70% | 53.07% | 50.67% | 46.30% | |
| Dtd | CoOp+JoAPR* | 56.63% | 56.63% | 56.77% | 53.07% | 49.40% | 46.83% | |
| Dtd | CoOp+BiC | 46.59% +- 4.00% | 54.93% +- 5.57% | 54.88% +- 2.09% | 54.43% +- 0.47% | 53.55% +- 0.27% | 37.59% +- 14.40% | 16.08% +- 20.81% |
| Dtd | CoOp+DPL | 63.53% +- 0.11% | 61.90% +- 0.93% | 61.21% +- 0.14% | 56.99% +- 1.17% | 55.40% +- 1.99% | 49.94% +- 0.95% | 42.00% +- 1.97% |
| Dtd | CoOp+Bert | 61.82% +- 3.20% | 61.01% +- 0.46% | 58.96% +- 2.24% | 56.32% +- 2.51% | 53.68% +- 4.24% | 48.84% +- 4.53% | 41.21% +- 7.06% |
| Dtd | CoOp+BertClean | 61.03% +- 1.83% | 62.67% +- 0.87% | 60.60% +- 1.67% | 59.26% +- 0.36% | 57.05% +- 0.49% | 55.46% +- 1.48% | 45.23% +- 2.82% |
| Oxford_pets | CoOp | 77.67% | 69.23% | 58.73% | 48.37% | 35.37% | 22.37% | |
| Oxford_pets | PTNL | 87.89% | 84.62% | 81.20% | 73.13% | |||
| Oxford_pets | CoOp+JoAPR | 85.20% | 85.40% | 85.27% | 85.67% | 85.30% | 83.77% | |
| Oxford_pets | CoOp+JoAPR* | 85.93% | 86.13% | 85.17% | 86.27% | 84.53% | 83.10% | |
| Oxford_pets | CoOp+BiC | 84.90% +- 3.33% | 83.07% +- 0.79% | 74.31% +- 8.84% | 82.16% +- 3.12% | 83.13% +- 0.57% | 79.69% +- 5.17% | 67.28% +- 9.42% |
| Oxford_pets | CoOp+DPL | 89.52% +- 0.28% | 88.70% +- 0.07% | 87.81% +- 0.66% | 86.81% +- 0.65% | 85.69% +- 0.55% | 80.20% +- 1.31% | 74.92% +- 2.65% |
| Oxford_pets | CoOp+Bert | 89.57% +- 1.30% | 88.88% +- 1.08% | 85.26% +- 1.81% | 79.35% +- 11.59% | 82.48% +- 4.89% | 77.39% +- 6.69% | 64.22% +- 7.49% |
| Oxford_pets | CoOp+BertClean | 88.87% +- 0.62% | 89.60% +- 1.00% | 89.72% +- 0.76% | 89.22% +- 0.83% | 88.00% +- 0.47% | 84.41% +- 0.31% | 74.42% +- 2.70% |
| Ucf101 | CoOp | 68.73% | 64.43% | 58.37% | 51.83% | 43.67% | 30.30% | |
| Ucf101 | PTNL | 73.12% | 68.73% | 67.66% | 60.93% | |||
| Ucf101 | CoOp+JoAPR | 73.90% | 73.17% | 72.77% | 70.00 % | 67.10% | 65.40% | |
| Ucf101 | CoOp+JoAPR* | 73.37% | 73.83% | 71.40% | 70.30% | 66.83% | 63.80% | |
| Ucf101 | CoOp+BiC | 51.44% +- 18.32% | 44.72% +- 35.20% | 22.74% +- 34.79% | 33.62% +- 29.03% | 12.12% +- 18.04% | 13.67% +- 20.52% | 25.17% +- 21.66% |
| Ucf101 | CoOp+DPL | 74.12% +- 0.57% | 72.85% +- 0.79% | 71.68% +- 0.69% | 70.69% +- 0.57% | 68.67% +- 0.88% | 65.55% +- 0.34% | 59.19% +- 1.14% |
| Ucf101 | CoOp+Bert | 77.19% +- 0.96% | 77.38% +- 1.34% | 76.80% +- 2.80% | 74.88% +- 3.47% | 73.36% +- 4.90% | 71.62% +- 5.24% | 65.69% +- 5.71% |
| Ucf101 | CoOp+BertClean | 76.85% +- 0.44% | 78.15% +- 0.91% | 77.34% +- 0.98% | 76.91% +- 0.64% | 76.24% +- 0.83% | 75.00% +- 1.54% | 68.99% +- 2.39% |
四、算法伪代码

五、存在的问题以及后续改进
- 存在的问题:对于噪声率较高情形,鲁棒性较差;
- 可能的问题:对于噪声率较高情形,大部分样本标签是不正确的,判别器在评估伪标签时,没有经过评估的伪标签也将很可能是噪声的,再用原始的标签就会造成错误引导。
- 后续改进:在 $Y_L$ 上改进,不直接使用原始标签;
后续优化
一、自适应阈值算法
OTSU算法(大津法——最大类间方差法)
二、正负样本生成伪标签
- 干净数据集
- $(X, Y)$:正样本,置信度高;
- $(X, Y’)$:负样本,相似度高/次高;
- 噪声数据集
- $(X, Y)$:负样本,噪声标签
- $(X, Y’)$:正样本,置信度高;
三、去除低质量标签组
对于低质量标签组,我们认为该类样本即使经过标签增强也仍包含较大噪声而无法通过判别器的筛选,因此我们考虑直接弃用该类样本。
- 实施方法
- 设定筛选阈值为 0.5:使得判别器滤除了较多样本,我们考虑的原因是多模态编码器采用的VE任务的预训练模型权重,其本身为三分类任务,而且我们没有对最后的Forward Network进行微调。这将会导致存在部分偏差。
- 设定阈值为 0.4:我们进一步地设定阈值为 0.4,发现对于所有数据集训练即使是噪声率较高情形下,都能够筛选出一定数量的具有高质量标签的样本,与Ground Truth匹配度需要进一步验证【TODO】。
- 效果表现
- 我们设定阈值为 0.4,在四个数据集上进行了实验。实验结果发现,1,对于大部分噪声率情形均有所提升;2,对于噪声率较高情形下,有较大的提升;
- 具体实验结果见上表:【RPL】中 CoOp+BertClean
四、判别器监督学习
- 损失函数
- 对齐损失:文本特征,图像
- 预测损失:
- 生成器对应到GMM
- 预测的概率建立GMM,Batch/Epoch/5epoch
五、分析中间结果与可视化概率分布
中间结果分析
样本属性
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18|---Epoch 0
|---<label> # 原始噪声标签
|---<gt_label> # 干净标签 ground truth
|---<lossG> # 生成器预测样本平均损失
|---<probsG> # GMM 预测标签干净概率
|---<pred_labelG> # 生成器预测的伪标签
|---<refurbished_label> # 翻新的伪标签
|---<probsD> # 判别器预测的标签匹配概率
|---Epoch 10
|---...
|---Epoch 20
|---...
|---Epoch 30
|---...
|---Epoch 40
|---...
|---Epoch 50
|---...- 统计数据组织结构:
{'Epoch 1': [{attri: value}, ...], ...}
- 统计数据组织结构:
评估指标
生成器有效性
- 模式分析
- 相关数据:噪声标签label,预测的伪标签 pred_labelG;
- TP 样本:label 是正确的标签,pred_labelG 也是正确的标签;
- TN 样本:label 是错误的标签,pred_labelG 是错误的标签;
- FN 样本:label 是正确的标签,pred_labelG 是错误的标签;
- FP 样本:label 是错误的标签,pred_labelG 是正确的标签;
- 保持能力:$Recall = TP/(TP+FN)$
主要衡量:生成器模型保持正确标签的能力,取决于预训练阶段学习的知识;不能将原本正确的标签预测错误;
指标优化:越大越好;
- 纠错能力:$FP/(TN+FP)$
主要衡量:对于本来就是错误的标签,将其纠正为正确标签的能力;
指标优化:越大越好;
- 模式分析
标签翻新有效性
- 模式分析
- 相关数据:生成器预测的伪标签 pred_labelG,翻新的伪标签 refurbished_label
- TP 样本:pred_labelG 预测是正确的标签,refurbished_label 也是正确的标签;
- TN 样本:pred_labelG 预测是错误的标签,refurbished_label 是错误的标签;
- FN 样本:pred_labelG 预测是正确的标签,refurbished_label 是错误的标签;
- FP 样本:pred_labelG 预测是错误的标签,refurbished_label 是正确的标签;
- 召回率:$Recall = TP/(TP+FN)$
主要衡量:生成器预测为正确的标签中,被翻新仍为正确的标签比率,从正确到正确的比率;可以反映翻新机制对正确伪标签的保持能力,不破坏生成器预测的正确标签;
指标优化:越大越好
- 纠错能力:$FP/(TN+FP)$
主要衡量:翻新机制的纠错能力,对于生成器所有预测为错误标签的样本,计算被翻新为正确标签的样本占比;
指标优化:越大越好;
- 翻新精确率:$(TP+FP)/(TP+TN+FN+TP)$
主要衡量:对于所有样本,最终翻新为正确标签的样本所占比率;
指标优化:越大越好;
- 模式分析
判别器有效性
- 模式分析
- 相关数据:预测的匹配概率 probsD
- 需要进一步确定判别器选出的样本中,高质量标签组中干净样本所占比例;
- 模式分析
可视化概率分布
在模型整体架构中,首先针对样本预测损失建立GMM模型,这需要对样本损失分布进行分析,再者判别器预测的匹配概率,具有一定的分布特征,也需要进一步研究。
结果输出
实验设置:Caltech101,RN_50,CLIP+Bert
CLIP 预测样本的平均损失

GMM 建模后样本的干净概率分布

Bert 对翻新标签的质量评估

结果表明,对于判别器而言,其对于翻新的标签没有起到筛选作用,干净样本和噪声样本的评估概率分布几乎一致。
可能的原因:多模态融合编码器语义没有对齐;
存在的问题:
- 图文匹配主要是针对一张图像进行文本描述,在对伪标签做质量评估时,”a photo of a
with right label” 或者是 “the photo comes from “ 描述语义并不完整。 - 提示学习器的使用,将描述文本变为
- 图文匹配主要是针对一张图像进行文本描述,在对伪标签做质量评估时,”a photo of a
优化与改进
- 加载预训练模型 AEBEF
- 实验设置:75%噪声率,DTD数据集,CLIP+Bert
- 提示词:”In the photo, there is a
“ - 使用 VE 任务的描述,输出3个概率
- 结果:39.60%
- 使用二分类判别,结果只有 “30.50%”
- 提示词:”In the photo, there is a
六、跨模态编码器初始化参数
- bert
七、Bert文本编码器特点
- BERT通过在大规模文本数据上的预训练,学习到了深层次的语言特征,能够捕捉prompt text的语义和语境信息。
- BERT的双向训练机制使其能够同时考虑上下文中的前后文信息,有助于理解prompt text中词汇和句子的真正含义,这有助于判断图像与文本是否匹配。
- BERT将文本特征与视觉特征相结合,有助于在视觉-语言任务中进行有效的跨模态信息融合和交互。
- BERT的上下文理解能力有助于模型在面对模糊或歧义的文本描述时做出更准确的判断,提高模型在视觉-语言任务中的鲁棒性。
八、分析GMM划分后的$$y_i$$
分析GMM区分的干净数据和噪声数据,对于负样本数据能不能引入其他提示信息使label变正确
GMM通过对损失建模,置信概率probs大于阈值的被划分为干净数据,小于阈值的被划分为噪声数据
九、图文匹配优化
增加文本提示掩码以及创建文本提示学习器

有一些初步效果,判别器对两类样本开始逐渐有些分离趋势。
提示词对比
- “In the photo there is a”:BertSimple
- GPT 扩展生成特征描述:BertGPT
- GPT 扩展生成多条提示词,集成多条提示词
| Dataset | Method | Noise Rate | Noise Rate | Noise Rate | Noise Rate | Noise Rate | Noise Rate | Noise Rate |
|---|---|---|---|---|---|---|---|---|
| 0 | 12.5% | 25.0% | 37.5% | 50% | 62.5% | 75.0% | ||
| Caltech101 | CoOp | 79.03% | 70.60% | 65.70% | 57.57% | 47.20% | 36.67% | |
| Caltech101 | PTNL | 90.65% | 82.51% | 78.70% | 70.13% | |||
| Caltech101 | CoOp+JoAPR | 88.50% | 89.07% | 88.47% | 89.03% | 87.67% | 84.87% | |
| Caltech101 | CoOp+JoAPR* | 89.20% | 89.30% | 89.60% | 88.83% | 87.10% | 85.20% | |
| Caltech101 | CoOp+BertSimple | 90.19% +- 0.02% | 90.85% +- 0.23% | 91.17% +- 0.25% | 90.67% +- 0.27% | 90.90% +- 0.34% | 89.20% +- 1.52% | 88.26% +- 0.50% |
| Caltech101 | CoOp+BertGPT | 90.19% +-0.02% | 91.00% +- 0.30% | 91.22% +- 0.23% | 90.71% +- 0.49% | 90.93% +- 0.30% | 89.20% +- 1.52% | 88.26% +- 0.50% |
| Dtd | CoOp | 55.50% | 49.27% | 43.83% | 36.00% | 27.23% | 19.77% | |
| Dtd | PTNL | 62.86% | 58.90% | 53.62% | 46.19% | |||
| Dtd | CoOp+JoAPR | 58.83% | 57.67% | 55.70% | 53.07% | 50.67% | 46.30% | |
| Dtd | CoOp+JoAPR* | 56.63% | 56.63% | 56.77% | 53.07% | 49.40% | 46.83% | |
| Dtd | CoOp+BertGPT | 59.30% +- 0.46% | 59.02% +- 1.25% | 58.51% +- 1.27% | 56.78% +- 0.95% | 55.06% +- 2.00% | 51.32% +- 1.88% | 43.42% +- 1.45% |
| Dtd | CoOp+BertGPT5 | 58.59% +- 0.55% | 58.81% +- 0.91% | 58.63% +- 0.72% | 57.11% +- 1.15% | 54.69% +- 1.39% | 50.26% +- 2.09% | 46.22% +- 1.43% |
| Oxford_pets | CoOp | 77.67% | 69.23% | 58.73% | 48.37% | 35.37% | 22.37% | |
| Oxford_pets | PTNL | 87.89% | 84.62% | 81.20% | 73.13% | |||
| Oxford_pets | CoOp+JoAPR | 85.20% | 85.40% | 85.27% | 85.67% | 85.30% | 83.77% | |
| Oxford_pets | CoOp+JoAPR* | 85.93% | 86.13% | 85.17% | 86.27% | 84.53% | 83.10% | |
| Oxford_pets | CoOp+BertSimple | 88.30% +- 0.27% | 87.88% +- 0.44% | 87.82% +- 0.74% | 87.25% +- 1.34% | 86.46% +- 1.34% | 84.03% +- 1.77% | 70.23% +- 6.57% |
| Oxford_pets | CoOp+BertGPT | 88.31% +- 0.27% | 87.88% +- 0.44% | 87.82% +- 0.74% | 87.27% +- 1.37% | 86.46% +- 1.34% | 82.98% +- 2.06% | 71.60% +- 3.28% |
| Ucf101 | CoOp | 68.73% | 64.43% | 58.37% | 51.83% | 43.67% | 30.30% | |
| Ucf101 | PTNL | 73.12% | 68.73% | 67.66% | 60.93% | |||
| Ucf101 | CoOp+JoAPR | 73.90% | 73.17% | 72.77% | 70.00 % | 67.10% | 65.40% | |
| Ucf101 | CoOp+JoAPR* | 73.37% | 73.83% | 71.40% | 70.30% | 66.83% | 63.80% | |
| Ucf101 | CoOp+BertSimple | 71.76% +- 0.39% | 73.85% +- 0.24% | 72.36% +- 0.69% | 72.17% +- 0.94% | 71.16% +- 0.59% | 68.69% +- 0.88% | 64.30% +- 0.75% |
| Ucf101 | CoOp+BertGPT | 71.76% +- 0.39% | 74.26% +- 0.62% | 72.53% +- 0.86% | 72.51% +- 0.41% | 70.68% +- 0.94% | 68.57% +- 0.63% | 64.43% +- 0.68% |
十、其他思路
思路一:优化噪声样本集
对于经过GMM建模损失划分的数据集,引入置信度进行质量评估,划分为干净样本的置信概率大于设定的自适应阈值且预测标签等于原有的噪声标签,不用翻新;置信概率大于自适应阈值但预测标签不等于原有的噪声标签,则重新打标签,而置信概率低于阈值的,直接划分为不确定组;
$$
p_i > \tau 且 \tilde{y_i} = y_i, Absorb\ p_i > \tau 且 \tilde{y_i} \neq y_i, Relabel\ p_i <= \tau , ReMatch
$$
自适应阈值 $$\tau$$
初始设置 $$\tau$$ 为 0.5,然后设当前 epoch 筛选出的干净样本数为$$N_c$$,总样本数为 N 则 下一个 epoch: $$\tau$$ = $$\tau$$ * (1+$$N_c$$ / N)
重新匹配(ReMatch)对于未确定的样本集,利用图文匹配预训练模型,针对图像样本构建多条特定类别的特征文本提示词,细化特征匹配,得到类别标签是否干净的概率值;如果匹配上且置信度较高,则Absorb,如果未匹配上,则弃用。可以利用图文匹配预训练模型的零样本推理能力。
思路二:引入BLIP预训练模型进行匹配
对翻新的伪标签,利用BLIP评估伪标签质量,前提是BLIP需要在图文匹配上面调整效果较好。如果伪标签质量较高,则Absorb,否则弃用;
思路三:类别不平衡——优化CLIP提示学习器
对学习困难的类别逐渐引入额外的特征提示词,学习容易的类别之引入类别标签,每个epoch需要评估数据集,测每个类别准确率,小于一定阈值认为为难学习类别,下一个epoch引入一定数量(参照准确率)特征提示。专门设计为鲁棒性提示学习而言的。
十一、BLIP:图文匹配测试
实验配置
- Dtd数据集,两个类别:banded,blotchy
- 图文匹配,预训练的BLIP输出,
- <1> ITM: 图像文本匹配的概率值
该任务将文本图像特征在跨模态编码器中进行了融合,输出是否匹配的二分类概率值。
- <2> ITC: 图像文本匹配的相似度
将文本图像的特征投影到同一维度空间计算余弦相似度。
简单测试分析
- banded的提示匹配banded的图像
1 | loading pretrained model from the directory: ./checkpoints/model_base_retrieval_coco.pth |
- banded的提示匹配blotchy的图像
1 | loading pretrained model from the directory: ./checkpoints/model_base_retrieval_coco.pth |
- blotchy的提示匹配blotchy的图像
1 | loading pretrained model from the directory: ./checkpoints/model_base_retrieval_coco.pth |
- blotchy的提示匹配banded的图像
1 | loading pretrained model from the directory: ./checkpoints/model_base_retrieval_coco.pth |
结果分析
- 每个类别设置多条提示词的重要性
对于给定的类别,设置的类别特征描述对最终图文匹配概率预测有比较关键的影响,这可以增加匹配的鲁棒性;
- 图文匹配概率值趋向两个分布
虽然利用预训练模型对下游数据集进行图文匹配不能够完全达到上游任务较高的匹配概率(>0.9),但是对于文本提示和图像不匹配的情况,筛选作用很有表现力。这说明图文匹配预训练模型能够筛选出明显不匹配的图像文本对,这将使得匹配概率趋向于两个分布,可以进一步用GMM建模。
实验结果
- 实验配置:固定BLIP文本提示词,对未确定样本集进行匹配;—— CoOp+BLIP
| Dataset | Method | Noise Rate | Noise Rate | Noise Rate | Noise Rate | Noise Rate | Noise Rate | Noise Rate |
|---|---|---|---|---|---|---|---|---|
| 0 | 12.5% | 25.0% | 37.5% | 50% | 62.5% | 75.0% | ||
| Dtd | CoOp | 55.50% | 49.27% | 43.83% | 36.00% | 27.23% | 19.77% | |
| Dtd | PTNL | 62.86% | 58.90% | 53.62% | 46.19% | |||
| Dtd | CoOp+JoAPR | 58.83% | 57.67% | 55.70% | 53.07% | 50.67% | 46.30% | |
| Dtd | CoOp+JoAPR* | 56.63% | 56.63% | 56.77% | 53.07% | 49.40% | 46.83% | |
| Dtd | CoOp+BiC | 46.59% +- 4.00% | 54.93% +- 5.57% | 54.88% +- 2.09% | 54.43% +- 0.47% | 53.55% +- 0.27% | 37.59% +- 14.40% | 16.08% +- 20.81% |
| Dtd | CoOp+BertSimple | 59.14% +- 0.27% | 60.52% +- 1.94% | 58.45% +- 0.61% | 57.21% +- 1.04% | 55.42% +- 0.79% | 52.42% +- 0.29% | 43.75% +- 0.83% |
| Dtd | CoOp+BertGPT | 59.30% +- 0.46% | 59.02% +- 1.25% | 58.51% +- 1.27% | 56.78% +- 0.95% | 55.06% +- 2.00% | 51.32% +- 1.88% | 43.42% +- 1.45% |
| Dtd | CoOp+BertGPT5 | 58.59% +- 0.55% | 58.81% +- 0.91% | 58.63% +- 0.72% | 57.11% +- 1.15% | 54.69% +- 1.39% | 50.26% +- 2.09% | 46.22% +- 1.43% |
| Dtd | CoOp+BLIP | 62.69% +- 0.16% | 62.19% +- 0.55% | 60.28% +- 1.01% | 58.49% +- 1.28% | 54.80% +- 1.23% | 49.43% +- 1.99% | 39.62% +- 0.93% |
存在的问题
BLIP对未确定组的匹配率较低,并且其中准确率接近数据集噪声率。
可能的分析
自我确认偏差,对于标签生成器而言,其作为训练中模型,将其较高置信度的输出作为干净样本,然后对较低置信度输出进行翻新,然后再对未确定的部分经过BLIP进行匹配;总体上而言,学习的模型只有CLIP,这种模式会导致CLIP不断趋向自己认为的方向,但不一定是正确的方向。
最直接的解决方法是,构建两个模型进行交互作用。
子任务
可视化图文匹配概率分布;
- 噪声率 75% 下,BLIP匹配概率分布

- 噪声率 75% 下,GMM拟合的分布

- 噪声率 75% 下,GMM实际对应的概率分布

- 噪声率 75% 下,BLIP匹配概率分布

- 噪声率 75% 下,GMM拟合的分布

- 噪声率 75% 下,GMM实际对应的概率分布

测试对伪标签生成器翻新的标签进行匹配,然后利用BLIP从中筛选高质量样本,再给CLIP学习,这个过程中BLIP不进行学习;——CoOp+BLIPAll
这样会使得CLIP翻新的标签仍需要经过BLIP验证,但是也会存在这样一个问题,BLIP匹配率和准确性将会较大程度上影响CLIP学习到的知识。进一步探索BLIP能力,结合利用图文匹配的相似度。【TODO】
| Dataset | Method | Noise Rate | Noise Rate | Noise Rate | Noise Rate | Noise Rate | Noise Rate | Noise Rate |
|---|---|---|---|---|---|---|---|---|
| 0 | 12.5% | 25.0% | 37.5% | 50% | 62.5% | 75.0% | ||
| Caltech101 | CoOp | 79.03% | 70.60% | 65.70% | 57.57% | 47.20% | 36.67% | |
| Caltech101 | PTNL | 90.65% | 82.51% | 78.70% | 70.13% | |||
| Caltech101 | CoOp+JoAPR | 88.50% | 89.07% | 88.47% | 89.03% | 87.67% | 84.87% | |
| Caltech101 | CoOp+JoAPR* | 89.20% | 89.30% | 89.60% | 88.83% | 87.10% | 85.20% | |
| Caltech101 | CoOp+BLIP | 91.10% +- 0.58% | 90.98% +- 0.56% | 90.90% +- 0.11% | 90.20% +- 0.39% | 86.11% +- 1.33% | 80.47% +- 2.27% | 69.84% +- 1.63% |
| Caltech101 | CoOp+BLIPAll | 89.43% +- 0.41% | 90.30% +- 0.10% | 90.41% +- 0.11% | 90.49% +- 0.21% | 90.45% +- 0.40% | 90.24% +-0.38% | 90.15% +- 0.66% |
| Caltech101 | CoOp+BLIPITC | 90.57% +- 0.34% | 90.86% +- 0.18% | 90.87% +- 0.52% | 90.63% +- 0.56% | 90.52% +- 0.04% | 90.35% +- 0.17% | 89.29% +- 0.44% |
| Dtd | CoOp | 55.50% | 49.27% | 43.83% | 36.00% | 27.23% | 19.77% | |
| Dtd | PTNL | 62.86% | 58.90% | 53.62% | 46.19% | |||
| Dtd | CoOp+JoAPR | 58.83% | 57.67% | 55.70% | 53.07% | 50.67% | 46.30% | |
| Dtd | CoOp+JoAPR* | 56.63% | 56.63% | 56.77% | 53.07% | 49.40% | 46.83% | |
| Dtd | CoOp+BLIP | 62.69% +- 0.16% | 62.19% +- 0.55% | 60.28% +- 1.01% | 58.49% +- 1.28% | 54.80% +-1.23% | 49.43% +- 1.99% | 39.62% +- 0.93% |
| Dtd | CoOp+BLIPAll | 55.69% +- 0.79% | 55.89% +- 0.56% | 54.59% +- 1.00% | 54.55% +- 0.61% | 52.96% +- 1.20% | 51.26% +- 1.92% | 49.23% +- 0.22% |
| Dtd | CoOp+BLIPITC | 58.94% +- 0.50% | 61.15% +- 1.71% | 58.96% +- 1.76% | 57.45% +- 0.88% | 54.59% +- 0.74% | 51.93% +- 1.05% | 45.96% +- 0.91% |
| Oxford_pets | CoOp | 77.67% | 69.23% | 58.73% | 48.37% | 35.37% | 22.37% | |
| Oxford_pets | PTNL | 87.89% | 84.62% | 81.20% | 73.13% | |||
| Oxford_pets | CoOp+JoAPR | 85.20% | 85.40% | 85.27% | 85.67% | 85.30% | 83.77% | |
| Oxford_pets | CoOp+JoAPR* | 85.93% | 86.13% | 85.17% | 86.27% | 84.53% | 83.10% | |
| Oxford_pets | CoOp+BLIP | 89.16% +- 0.19% | 87.64% +- 0.40% | 86.69% +- 0.89% | 85.37% +- 0.90% | 82.39% +- 1.24% | 74.62% +- 1.92% | 61.78% +- 1.26% |
| Oxford_pets | CoOp+BLIPAll | 88.14% +- 0.97% | 87.85% +- 1.69% | 88.46% +- 0.55% | 88.01% +- 0.58% | 86.69% +- 1.57% | 86.79% +- 0.89% | 82.14% +- 1.01% |
| Oxford_pets | CoOp+BLIPITC | 88.95% +- 0.24% | 87.81% +- 0.29% | 86.04% +- 0.51% | 84.39% +- 0.64% | 82.16% +- 1.65% | 76.90% +- 1.26% | 71.12% +- 1.77% |
| Ucf101 | CoOp | 68.73% | 64.43% | 58.37% | 51.83% | 43.67% | 30.30% | |
| Ucf101 | PTNL | 73.12% | 68.73% | 67.66% | 60.93% | |||
| Ucf101 | CoOp+JoAPR | 73.90% | 73.17% | 72.77% | 70.00 % | 67.10% | 65.40% | |
| Ucf101 | CoOp+JoAPR* | 73.37% | 73.83% | 71.40% | 70.30% | 66.83% | 63.80% | |
| Ucf101 | CoOp+BLIP | 73.61% +- 0.64% | 74.15% +- 0.88% | 72.68% +- 0.84% | 72.43% +- 0.38% | 70.94% +- 1.31% | 68.13% +- 0.51% | 63.32% +- 0.83% |
| Ucf101 | CoOp+BLIPAll | 66.32% +- 0.51% | 66.87% +- 0.75% | 66.74% +- 0.53% | 66.49% +- 1.05% | 65.99% +- 0.20% | 65.70% +- 0.85% | 64.52% +- 1.50% |
| Ucf101 | CoOp+BLIPITC | 71.72% +- 0.52% | 73.12% +- 1.03% | 71.25% +- 0.78% | 70.53% +- 0.84% | 68.59% +- 0.18% | 66.28% +- 0.48% | 62.21% +- 0.40% |
可视化分析
- 噪声率 75% 下,BLIP匹配概率分布

- 噪声率 75% 下,GMM拟合的分布

- 噪声率 75% 下,GMM实际对应的概率分布

实验结果分析
- BLIP在低噪声率情形下表现较好,而BLIPAll在高噪声情形下表现较好;
- 说明,BLIP对翻新后的伪标签存在扰动因素,并且在高噪声情形下,CLIP预测置信度高的作为干净样本,会引入较大的自我确认误差;
- 为BLIP设置提示学习器,进行提示学习;
其中利用GMM判定的伪标签为BLIP提供监督,匹配后的样本为CLIP提供监督。
- 构建动态训练数据集,不断优化样本标签,不断添加高质量样本;
问题:BLIP作为预训练模型,对数据集中所有样本预测的匹配概率分布几乎在50个epoch中保持不变,说明翻新的伪标签变化程度不够。
解决方法:
- 设置提示学习器
- 优化伪标签,对于判定为噪声样本的对原始标签进行标签更新。
任务清单
- 为 CLIP 构建动态提示学习器;
- 为 BLIP 设置提示学习器;
- 构建交互作用,解决自我确认偏差问题;
- 构建动态训练数据集;
- 探索 ITC 计算结果作用;
数据集划分
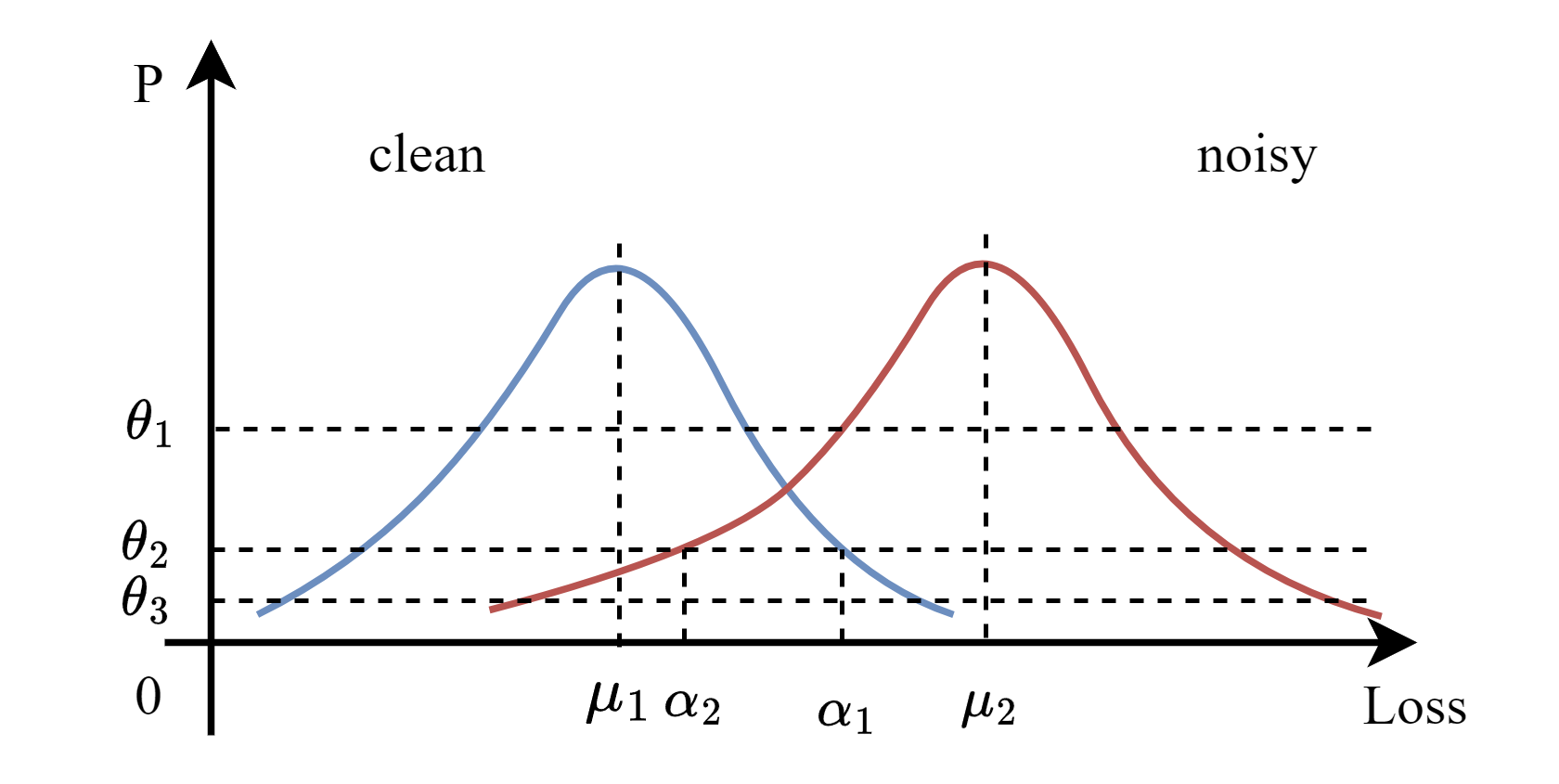
对于干净和噪声数据集的两种损失分布,如上图所示,假设干净样本损失分布:$X\sim N(\mu_1,\sigma_1^2)$,噪声样本损失分布:$U\sim N(\mu_2, \sigma_2^2)$,有如下概率密度分布
$$
\begin{aligned}
f_X(x)&=\frac{1}{\sigma_1\sqrt{2\pi}}e^{-\frac{(x-\mu_1)^2}{2\sigma_1^2}} <\theta\newline
f_U(x)&=\frac{1}{\sigma_2\sqrt{2\pi}}e^{-\frac{(x-\mu_2)^2}{2\sigma_2^2}} <\theta
\end{aligned}
$$
解上式得:
$$
\begin{aligned}
\alpha_1&=\mu_1+\sqrt{-2\sigma_1^2\ln(\theta\sigma_1\sqrt{2\pi})}\newline
\alpha_2&=\mu_2-\sqrt{-2\sigma_2^2\ln(\theta\sigma_2\sqrt{2\pi})}
\end{aligned}
$$
- $\alpha_1 \leq \alpha_2$ 时,在置信度水平为 $1-\theta$ 条件下,两种数据分布没有重叠;
- $\alpha_1 > \alpha_2$ 时,在置信度水平为 $1-\theta$ 条件下,两种数据分布发生重叠,且重叠区域为 $\alpha_1-\alpha_2$;
据此,可以利用CLIP模型对整个数据集评估得样本损失,进行数据集划分,将其分为干净数据集,噪声数据集和混淆数据集。
划分后样本处理
- 对于干净数据集,执行 Absorb 操作 / 标签增强;
- 对于噪声数据集,CLIP生成伪标签;
- 对于混淆数据集,BLIP进行 ITC 预测,结合CLIP预测,生成伪标签;
- $refined_label = w * label + (1-w) * y_clip + (1-w)* y_blip$
伪标签评估
对于所有样本的伪标签,利用 BLIP 的图文匹配 (ITM),预测图像与特征提示的匹配概率,依据 GMM 建立模型选择匹配的样本和伪标签,进行模型学习。
- CLIP学习:$CE(CLIP(X_{match}), Y_{match})$
- BLIP学习:$CE(BLIP(X_{match}), Y_{match})$
整体框架
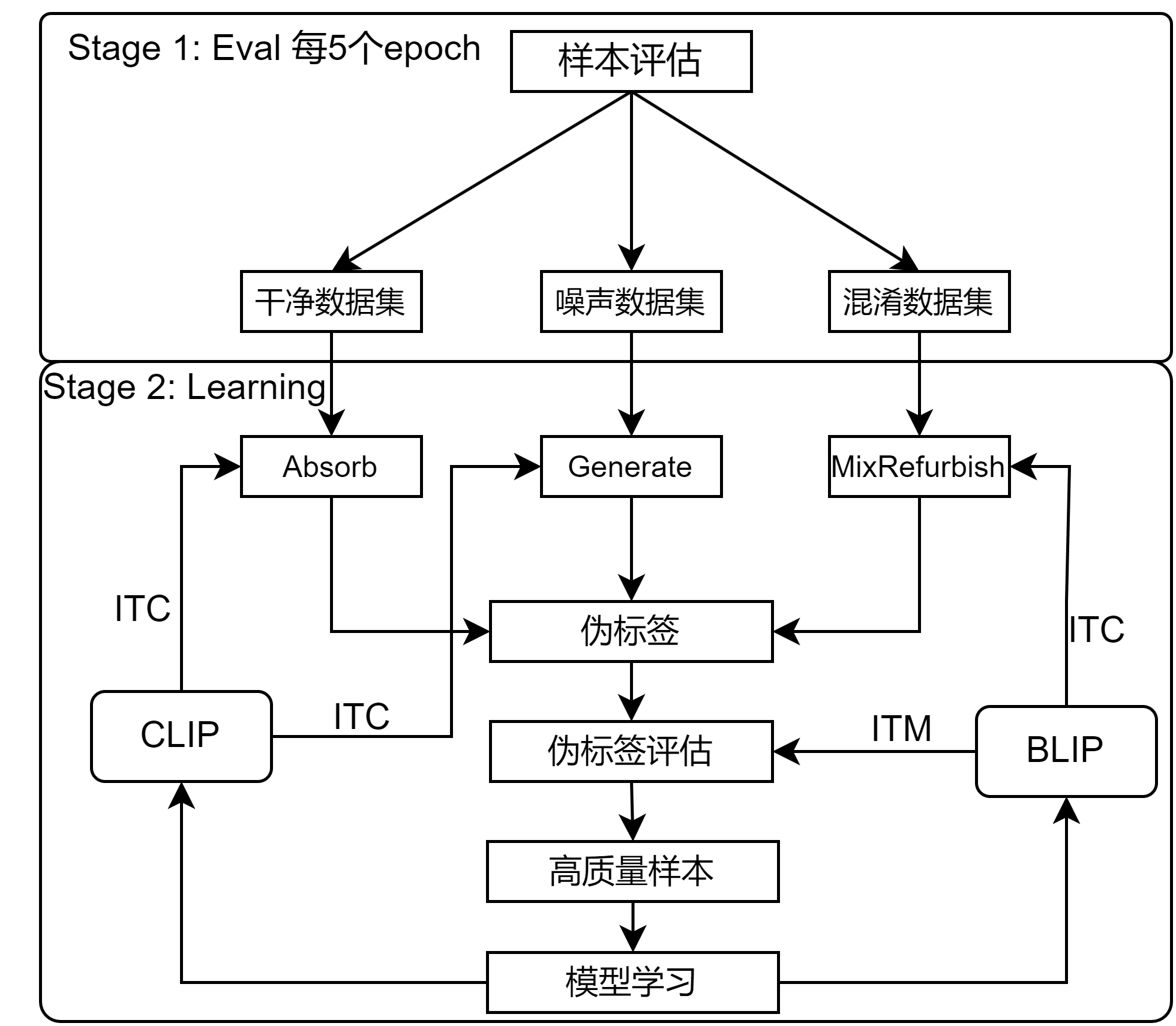
- 核心优势:
- 伪标签评估:在传统噪声标签领域,对噪声样本筛选,以及伪标签生成已经有很多做法,但是对于生成的伪标签质量评估并没有进行探索,我们依据视觉语言模型BLIP强大的跨模态语义表示能力,引入细化的类别特征对样本的伪标签进行匹配,并选取高质量的图文对进行模型学习。利用BLIP匹配后怎样处理,也可以进一步探索。
- 混淆数据集构造:引入混淆数据集,并且利用两个模型的综合预测生成混淆数据集的伪标签,避免了对于混淆数据分布样本的自我确认偏差问题,CLIP预测混淆的样本分布可以进一步由BLIP模型来纠正。
消融探究
MixRefine有效性
| Method | 0FP | 2FP | 4FP | 8FP | 12FP |
|---|---|---|---|---|---|
| CoOp | 62.60% | 61.90% | 55.70% | 42.00% | 28.60% |
| CoOp+JoAPR | 58.83% | 57.67% | 53.07% | 46.30% | |
| CoOp+JoAPR* | 56.63% | 56.63% | 53.07% | 46.83% | |
| CoOp+MixRefine | 58.00% | 58.20% | 59.00% | 54.80% | 33.00% |
通过对比在 CoOp和数据集筛选、标签翻新机制 MixRefine,可以得出:相比于CoOp,MixRefine的使用有效地提高了噪声情形下模型学习的鲁棒性。
方法对比探究
CoOp+FPL(Feature Prompt Learning)
每一个 epoch中,先进行数据集划分:干净数据集、噪声数据集、混淆数据集;
再进行标签翻新:
- 干净数据集:Absorb,保留不变;
- 噪声数据集:Refine,翻新增强;
- 混淆数据集:FeaturedRefine,引入类别特征进行分类;
- 干净数据集:Absorb,保留不变;
CoOp+FPL(Feature Prompt Learning)+BLIP
- 在方法一的基础上,
- 添加 BLIP 对伪标签的质量评估操作;
- 对于方法一翻新的伪标签,评估伪标签质量,选取质量较高的样本进行学习。
实验结果
- Dtd: symflip_gceFalse
| Method | 0FP | 2FP | 4FP | 6FP | 8FP | 10FP | 12FP | average |
|---|---|---|---|---|---|---|---|---|
| CoOp+JoAPR | 58.83% | 57.67% | 55.70% | 53.07% | 50.67% | 46.30% | 53.71% | |
| CoOp+JoAPR* | 56.63% | 56.63% | 56.77% | 53.07% | 49.40% | 46.83% | 53.22% | |
| CoOp+1FPL | 57.13 +- 0.54% | 58.50 +- 1.13% | 59.23 +- 2.56% | 55.03 +- 2.38% | 54.47 +- 2.50% | 44.50 +- 2.83% | 34.30 +- 2.34% | 51.88% |
| CoOp+5FPL | 58.80 +- 0.80% | 57.53 +- 1.60% | 59.37 +- 2.64% | 57.13 +- 1.72% | 55.03 +- 2.53% | 44.17 +- 5.25% | 34.43 +- 0.31% | 52.35% |
| CoOp+1FPL+BLIP | 54.2% | 54.7% | 54.8% | 54.6% | 51.2% | 52.5% | 51.4% |
- Dtd: pairflip_gceFalse
| Method | 0FP | 2FP | 4FP | 6FP | 8FP | 10FP | 12FP | average |
|---|---|---|---|---|---|---|---|---|
| CoOp+JoAPR | 57.33% | 55.13% | 55.03% | 48.53% | 45.00% | 32.53% | 53.71% | |
| CoOp+JoAPR* | 55.60% | 57.03% | 55.30% | 53.27% | 41.17% | 31.70% | 53.22% | |
| CoOp+1FPL | 58.50 +- 0.83% | 59.07 +- 0.90% | 57.93 +- 2.41% | 55.17 +- 2.47% | 41.27 +- 4.55% | 27.60 +- 8.70% | 16.47 +- 5.19% | 45.14% |
| CoOp+5FPL | 59.57 +- 1.04% | 59.57 +- 0.74% | 58.33 +- 0.53% | 53.73 +- 2.68% | 43.00 +- 4.41% | 28.27 +- 8.58% | 13.60 +- 3.89% | 45.15% |
存在的问题
- 样本量选择:对于BLIP评估伪标签质量,对于高噪声情形下,能够选取高质量的伪标签,但是选出的样本数相对于 16shots 而言有所减少,因此模型学习受到高噪声影响减小;但是在低噪声情形下,由于学习样本较少,带来学习能力的下降。
- 为什么低噪声情形下,筛选出的高质量伪标签不够多?
- 理想情况:低中噪声情形下,筛选出较多的高质量伪标签;高噪声情形下,筛选出尽量多的高质量伪标签;
- 优化思路
- 设定动态筛选阈值 $\tau$,评估数据集中的含噪程度
探究
- 提示词重置
- 初始化的提示词 + 动态学习的提示词
参考文献
SRRS 研究方法的探索历程