A Literature Survey about Why Is Prompt Tuning for Vision-Language Models Robust to Noisy Labels
I.Summary Overview
Background: A vision-language model can be adapted to a new classification task through few-shot prompt tuning. We find that such a prompt tuning process is highly robust to label noises.
Interest: Studying the key reasons contributing to the robustness of the prompt tuning paradigm.
Findings:
- the fixed classname tokens provide a strong regularization to the optimization of the model, reducing gradients induced by the noisy samples;
- the powerful pre-trained image-text embedding that is learned from diverse and generic web data provides strong prior knowledge for image classification.
II.Research Interests
The author studies the key reasons contributing to the robustness of the prompt tuning paradigm.
III.Problems Solved
In author’s work, they demonstrate that prompt tuning is robust to noisy labels, and investigate the mechanisms that enable this robustness.
IV.Previous Research
While prompt tuning has proven effective when training on downstream tasks with accurately annotated datasets, their robustness to noisy labels has been neglected.
V.Author’s Innovation
The author investigates the mechanisms that enable this robustness and proposes a simple yet effective method for unsupervised prompt tuning, showing that randomly selected noisy pseudo labels can be effectively used to enhance CLIP zero-shot performance.
VI.Author’s Contribution
- We demonstrate that prompt tuning for pre-trained vision-language models (e.g., CLIP) is more robust to noisy labels than traditional transfer learning approaches, such as model fine-tuning and linear probes.
- We further demonstrate that prompt tuning robustness can be further enhanced through the use of a robust training objective.
- We conduct an extensive analysis on why prompt tuning is robust to noisy labels to discover which components contribute the most to its robustness.
- Motivated by this property, we propose a simple yet effective method for unsupervised prompt tuning, showing that randomly selected noisy pseudo labels can be effectively used to enhance CLIP zero-shot performance. The proposed robust prompt tuning outperformed prior work on a variety of datasets, even though noisier pseudo-labels are used for self-training.
VII.Algorithm Flow
Recent Research
- CLIP: CLIP applies prompt engineering to incorporate the category information in the text input such that its pre-trained model can adapt to various image classification tasks without further training.
- CoOp: CoOp introduces learnable prompts optimized on target datasets to address CLIP’s problem
- ProDA: ProDA tackles CoOp’s issue by utilizing diverse prompts to capture the distribution of varying visual representations.
- UPL: UPL proposes a framework to perform prompt tuning without labeled data.
- TPT: TPT achieves zero-shot transfer by dynamically adjusting prompts using only a single test sample.
- Potential of prompt tuning: Label noise-robust learning
- Label noise-robust learning
- robust losses that tolerate noisy labels
- loss correction approaches that estimate a transition matrix to correct the predictions
- meta-learning frameworks that learn to correct the label noise in training examples
- regularization techniques that are customized to lower the negative impact of noise
Existing Problems
- CLIP: the design of a proper prompt is challenging and requires heuristics.
- CoOp: CoOp has also faced criticism for disregarding the diversity of visual representations.
Author’s Processing
- Demonstrate that prompt tuning on CLIP naturally holds powerful noise robustness.
- Explore the key factors behind such robustness.
- Show its application on unsupervised prompt tuning.
Constructed Model
CLIP
In the case of image classification, a normalized image embedding $\boldsymbol{f}^v$ is obtained by passing an image $\boldsymbol{x}$ through CLIP’s visual encoder, and a set of normalized class embeddings $[\boldsymbol{f}^t_i]^K_{i=1}$ by feeding template prompts of the form “A photo of a“ into CLIP’s text encoder.
$$
Pr(y=i|\boldsymbol{x})=\frac{\exp(sim(\boldsymbol{f}^v,\boldsymbol{f}^t_i))/\tau}{\sum_{j=1}^K\exp(sim(\boldsymbol{f}^v,\boldsymbol{f}^t_j))/\tau}
$$Prompt Tuning
The name of a class c is first converted into a classname embedding $\boldsymbol{w}\in R^d$ and prepended with a sequence of $M$ learnable tokens $\boldsymbol{p_m}\in R^d$ shared across all classes.
$$
P_c=[\boldsymbol{p_1}, \boldsymbol{p_2}, \cdots, \boldsymbol{p_M}, \boldsymbol{w_c}]\rightarrow \boldsymbol{f}^t_c
$$
CoOp optimizes the shared learnable tokens $\boldsymbol{p_1}, \boldsymbol{p_1}, \cdots, \boldsymbol{p_M}$ on a small labeled dataset $D = [(\boldsymbol{x_i}, c_i)^N_{i=1}]$ to minimize the cross-entropy loss
$$
L_{CE}=-E_{(\boldsymbol{x},c)\in D}[\log Pr(y=c|\boldsymbol{x})].
$$Robust Prompt Tuning
Further enhance this robustness by optimizing the learnable prompts using the generalized cross-entropy (GCE) loss
$$
L_{GCE}=E_{(\boldsymbol{x},c)\in D}[\frac{1-Pr(y=c|\boldsymbol{x})^q}{q}].
$$Author’s Conclusion: $q = 0.7$ leads to overall good performance across several experimental settings.
VIII.Robustness Analysis
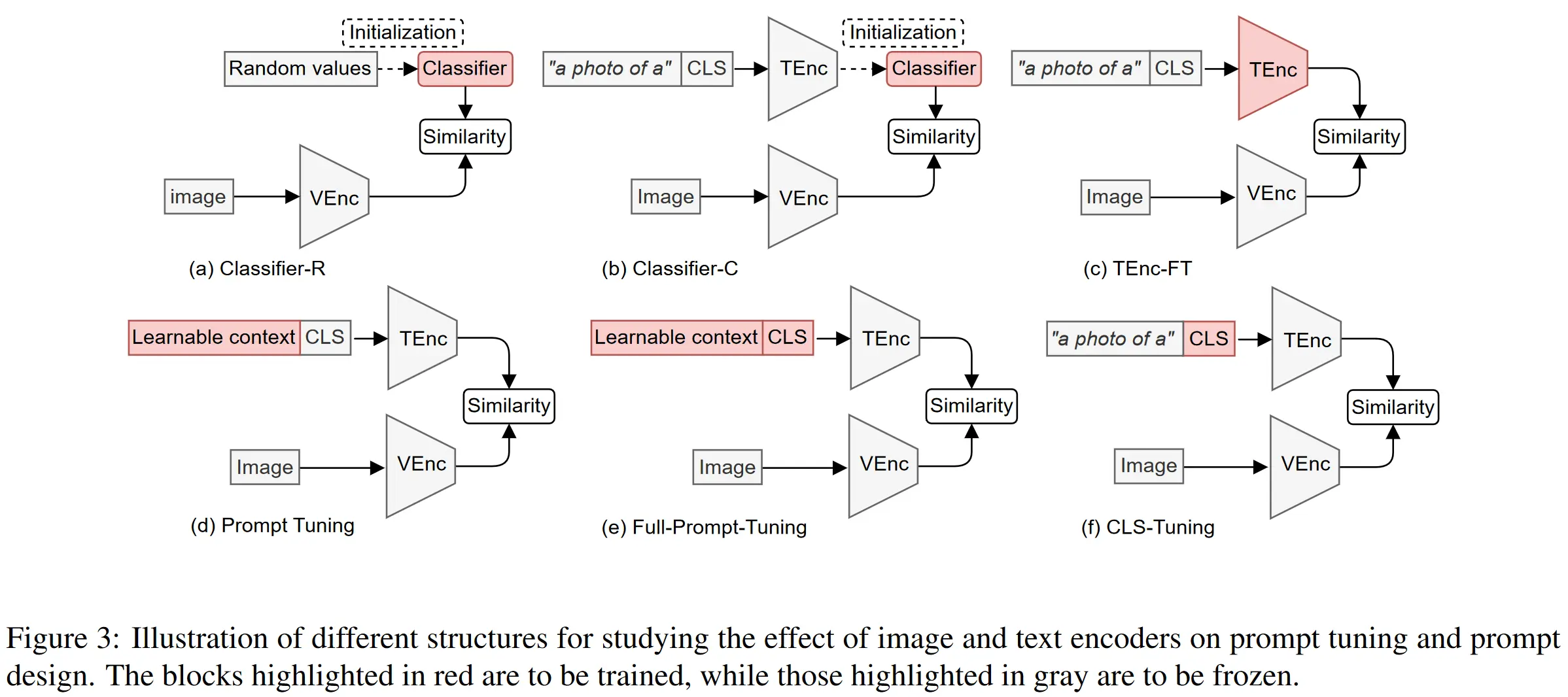
Pre-trained CLIP Generates Effective Class Embeddings
- Author’s Conclusions:
- Classifier-R v.s. Classifier-C: CLIP class embeddings provide a strong initialization for few-shot learning.
- TEnc-FT v.s. Classifier-C: The highly expressive CLIP text encoder can easily overfit to the noisy labels.
- Prompt Tuning v.s. Classifiers: The text encoder is essential for providing a strong but informative regularization of the text embeddings to combat noisy inputs.
- Prompt Tuning v.s. TEnc-FT: The text encoder should be fixed to prevent overfitting.
Effectiveness of Prompt
- Author’s Conclusions:
- Full Prompt Tuning v.s. CLS Tuning: The class embeddings generated by CLIP pre-trained text encoder plays a critical role in noise robustness.
- Hypothesis:
- The classname token $\boldsymbol{w_c}$ provides a strong regularization to the model, since it is leveraged by the text encoder to encode relationships between the different visual concepts.
Prompt Tuning Suppresses Noisy Gradients
- Prompt tuning can suppress gradient updates from noisy samples, while aggregating gradients from clean samples.
- This property likely arises from the highly constrained prompt tuning optimization, which restricting the model to fit the noisy labels.
Generalization Across Model Architectures
- Context length
- The optimal context length is dataset dependent.
- Image encoders
- ViT-B/32-PT outperforms RN50-PT under most settings. Moreover, both methods do not suffer from a large performance drop and maintain competitive accuracy at high noise rates.
Robustness to Correlated Label Noise
- Confusion noise: Each mislabeled sample is labeled as the incorrect class that is most favored by zero-shot CLIP.
- Author’s Conclusions:
- Confusion noise presents a bigger challenge to transfer learning, leading to larger degradation of classification accuracy at high noise ratios compared to random noise.
- Prompt tuning still achieves the best overall performance, providing further evidence for its robustness even to more challenging types of noise.
IX.Application to Unsupervised Prompt Tuning
- Baseline UPL
- Phase 1: Leverage pre-trained CLIP to generate pseudo labels for unlabeled images.
- Phase 2: Select the $K$ most confident samples per class to optimize the learnable tokens through the typical prompt-tuning optimization process (described in CoOp).
- Features: UPL improved transfer performance by ensembling multiple predictions generated by models with different learnable prompts.
- Robust UPL
- Overview: Based on UPL, randomly sample $K$ training samples and optimize the prompt with the robust GCE loss
X.Summary And Views
Summary
This paper focus on prompt tuning to research and analyze the attribution of robustness to label noise that it has naturally. And the author also combines the findings with the UPL model and proposes a more robust UPL model in unsupervised prompt tuning.
Personal Views
Firstly I learned a lot from this paper which analysis the robust of prompt tuning to label noise. This research spirit and methodology is a great need in motivating me to work on the research of robustness. And what’s impresses me most is the robust UPL model that is the author’s innovation about the previous research.
XI.Domain Learning
Related Terms
- Vision-language model
- text-image embedding and image-text embedding
- few-shot prompt tuning
- fixed classname tokens
- zero-shot learning
- downstream tasks: few-shot learning, continual learning, object segmentation
- model-informed structure
- traditional fine-tuning and linear probing paradigms
- generalized cross-entropy (GCE)
- VisionLanguage Pre-Trained Models (VL-PTMs)
- meta-learning
References
A Literature Survey about Why Is Prompt Tuning for Vision-Language Models Robust to Noisy Labels